
Introduction
The Architecture: How Zero-Copy Cloning Actually Works
Traditional Duplication vs. Metadata Cloning
How does Snowflake's metadata-driven approach compare to legacy database replication?
|
Feature |
Legacy Data Duplication |
|
|
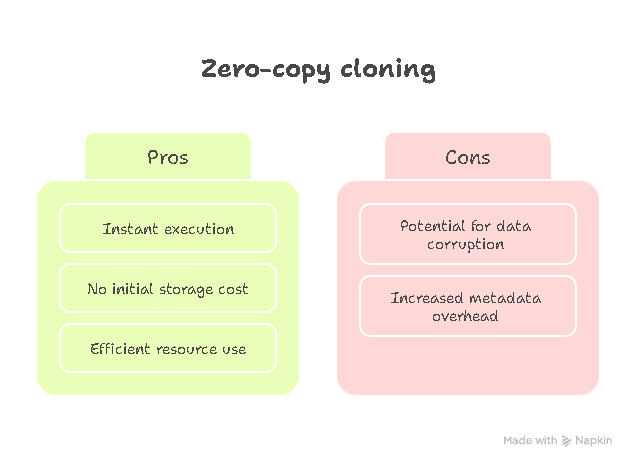
Execution Speed |
Hours to days (depends on data volume). |
Instantaneous (metadata operation only). |
|
Storage Cost |
2x storage multiplier immediately. |
$0 initial cost. Bills only for mutated delta records. |
|
Pipeline Overhead |
Requires heavy |
Single DDL command ( |
|
Compute Usage |
Consumes heavy warehouse processing power to move data. |
Uses zero virtual warehouse compute (handled by Cloud Services layer). |
Unlike legacy environments that require complex pipelines to move data, Snowflake handles cloning with a single Data Definition Language (DDL) command. You can clone at the table, schema, or database level:
-- Instantly clone a single table for a developer
CREATE TABLE sales_dev CLONE sales_prod;
-- Clone an entire schema without moving any physical data
CREATE SCHEMA marketing_qa CLONE marketing_prod;
Enterprise Engineering Use Cases
The Economic Impact: Reducing Cloud Spend
Best Practices & Governance
Conclusion: Scaling Agility
Book a Free 30-Minute Meeting
Discover how our services can support your goals — no strings attached. Schedule your free 30-minute consultation today and let's explore the possibilities.
Book a Free Call