Introduction
Core Concepts: Demystifying ETL-Driven Data Movement
Architectural Comparison: ETL vs. Migration vs. Integration
The 7-Stage ETL Data Migration Lifecycle
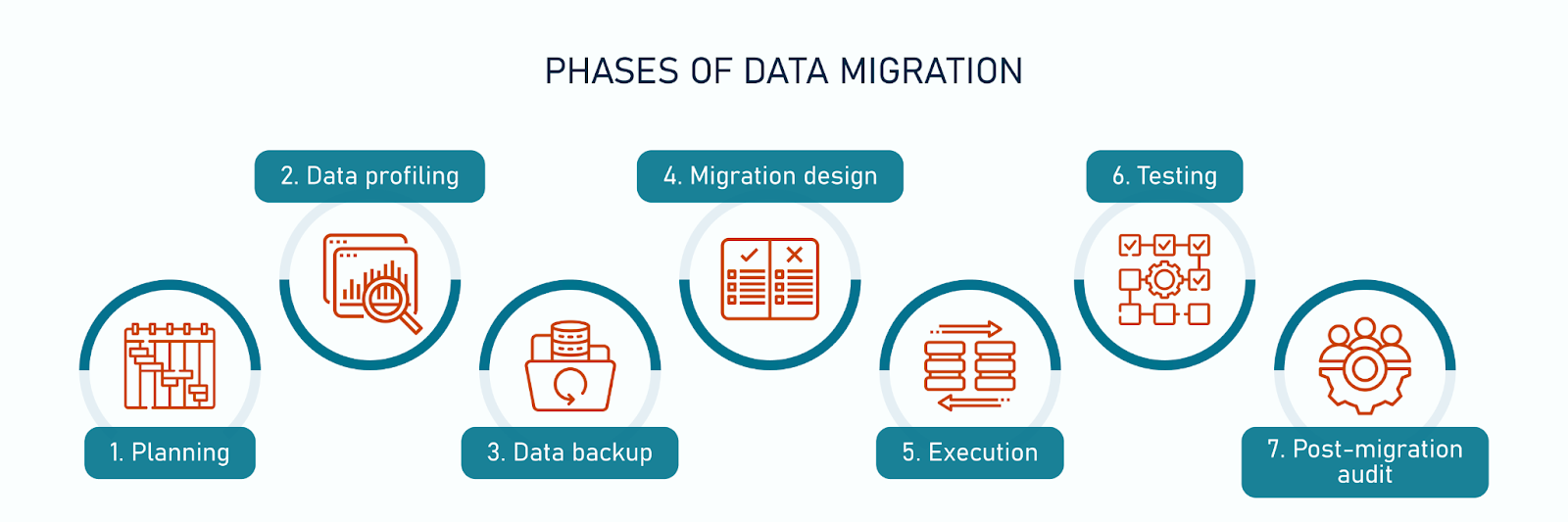
Phase 1: Planning
Establish defined boundaries for the migration project, identifying exactly which historical data schemas, tables, and system dependencies fall within the scope. This initial gate outlines strict compliance protocols, assigns stakeholder data ownership roles, and builds strategic contingency rollback paths to protect business continuity if network environments fail.
Phase 2: Data Assessment & Profiling (Bronze Zone Mapping)
Before writing a single transformation line, engineers must profile the raw source data to identify hidden irregularities. Running exploratory queries exposes null-value percentages, invalid strings, and broken records.
Phase 3: Data Backup
Generate immutable, point-in-time cold snapshots of all operational source environments before connecting external ingestion hooks or staging frameworks. This steps acts as an essential fallback layer, ensuring an exact copy of historical data remains completely isolated and secure.
Phase 4: Migration Design
Construct the core transformation architecture of your ETL/ELT pipelines. This is where you create source-to-target field mapping schemas, write explicit character typecasting rules, declare validation parameter thresholds, and configure error-routing logic to automatically isolate malformed rows into dead-letter queues.
Phase 5: Execution
Initialize active bulk data transfers and incremental delta sync loops. Modern enterprise structures deploy automated Change Data Capture (CDC) daemons to stream ongoing source database mutations directly into the target environment in parallel with daily live operations to eliminate system downtime.
Phase 6: Testing
Execute rigorous data quality validation cycles before finalizing the infrastructure cutover. Run targeted unit tests on individual orchestration workflows, perform integration smoke tests across relevant software tools, and conduct extensive User Acceptance Testing (UAT) using parallel runs to ensure financial ledgers match legacy reports exactly.
Phase 7: Post-Migration Audit
Following the loading cycle, teams perform a final end-to-end data validation check. Run automated cross-system row count reconciliations, verify that foreign key relationships and index parameters instantiated flawlessly, and execute cryptographic block-level checksum matches (such as MD5 or SHA-256) to prove perfect bit-level replication before turning off legacy systems.
This comprehensive Data Migration Life Cycle Guide breaks down how to systematically move enterprise datasets across all seven operational lifecycle gates while maintaining strict data quality parameters.
Evaluating the ETL Migration Stack: Tooling Ecosystem
Selecting the right integration framework depends on your existing cloud architecture, internal developer overhead, and compliance parameters:
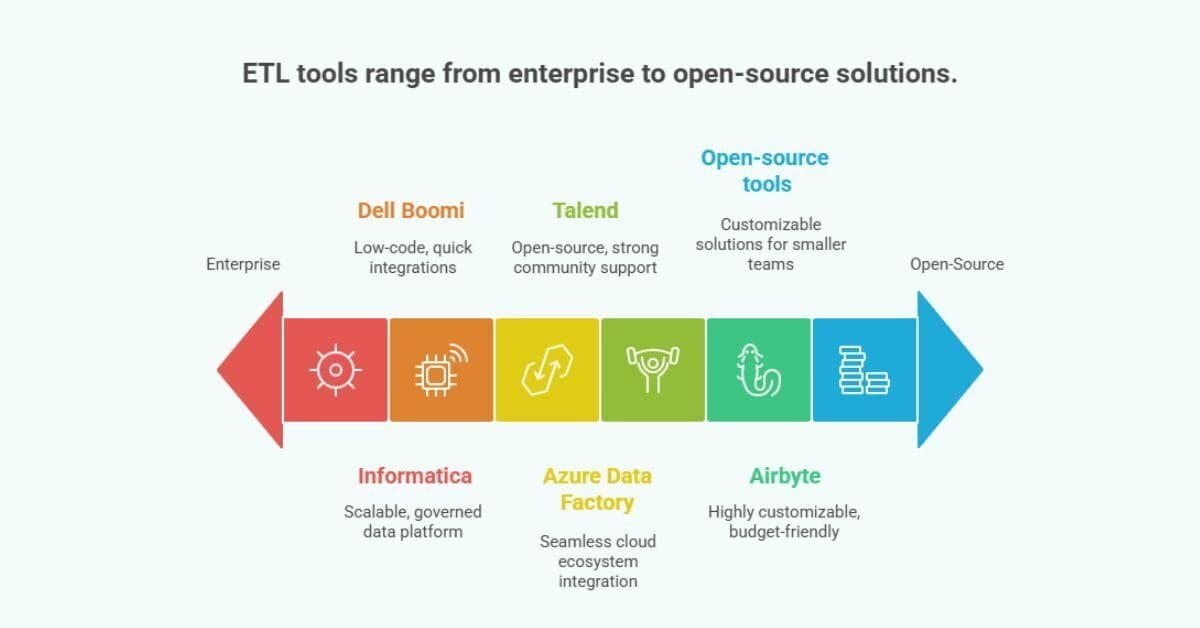
- Informatica PowerCenter: An enterprise-grade data integration platform tailored for massive legacy environments that require strict data governance controls, comprehensive security auditing, and high-throughput transformation engines.
- Talend Data Integration: An open-source-friendly, highly adaptable tool that provides extensive graphical development interfaces, native cloud connector suites, and strong community-driven plugin architectures.
- Azure Data Factory & AWS Glue: Cloud-native serverless integration tools optimized for environments already running on public cloud resources. Azure Data Factory Integration Services and AWS Glue provide seamless data lakehouse connectors, automated schema discovery, and effortless scalability.
- Airbyte: A modern, developer-centric open-source data movement engine that offers highly customizable code-based configurations and an extensive catalog of pre-built source-to-target connectors.
- Apache NiFi: A powerful, low-latency data flow management engine designed to handle continuous streaming data migration workloads with robust real-time lineage tracking.
The Production-Ready ETL Data Migration Checklist
Conclusion: Securing Pipeline Integrity
Book a Free 30-Minute Meeting
Discover how our services can support your goals — no strings attached. Schedule your free 30-minute consultation today and let's explore the possibilities.
Book a Free Call