Table of Contents

Introduction
As cloud warehouses like Snowflake and BigQuery continue to dominate modern analytics ecosystems, one challenge is becoming increasingly difficult to ignore:
Cloud compute costs are rising rapidly.
Teams are building more models, running more transformations, onboarding more analysts, and refreshing data more frequently than ever before. Yet despite this growth, most organizations lack visibility into the true cost structure of their dbt workloads. They see the warehouse bill, but they cannot pinpoint:
- which models consume the most compute
- which pipelines run more often than necessary
- where inefficient SQL patterns inflate costs
- how lineage sprawl increases warehouse load
- when developers unintentionally trigger expensive full refreshes
dbt Fusion introduces a fundamentally new approach to solving this problem.
With a Rust-powered engine, metadata-driven orchestration, and cost-aware compilation, dbt Fusion provides the insights and safeguards needed to control Snowflake and BigQuery spending without restricting development velocity.
This guide explains, in detail, how dbt Fusion improves cost efficiency across both platforms. You will learn:
- how Fusion estimates and prevents expensive query patterns
- how metadata improves orchestration and reduces unnecessary runs
- how the semantic layer eliminates redundant computations
- how compile-time validation prevents costly production errors
- real-world cost savings patterns observed across data teams
By the end, you will understand how dbt Fusion helps organizations reduce warehouse spend, streamline pipelines, and build more predictable, cost-efficient analytics operations.

Why dbt Core Was Cost-Blind
Before dbt Fusion, dbt Core had a significant limitation: it had no understanding of warehouse cost.
Core executed transformations, but it lacked the visibility and intelligence needed to optimize compute usage across Snowflake and BigQuery.
dbt Core could not interpret or predict:
- the cost impact of a model
- the warehouse size or compute tier the query would run on
- how long the transformation was expected to take
- whether a model refresh was necessary or wasteful
- whether an “incremental” model was actually operating incrementally
- whether upstream dependencies would trigger an expensive full refresh
As a result, analytics engineers wrote SQL in isolation from cost considerations. They were responsible for building high-quality data models, but they were largely unaware of how those models affected the warehouse bill. This often led to situations where teams:
- did not know which dbt models were responsible for increased Snowflake or BigQuery spend
- could not estimate cost impact during development or code review
- lacked visibility into production runtime degradation
- could not detect inefficient joins, filters, or model patterns early
- were unable to prioritize optimizations based on cost impact
- struggled to understand which parts of the DAG were the most expensive to maintain
This visibility gap became more severe as organizations scaled their dbt usage. More contributors meant more queries, more lineage depth, more refresh frequency, and ultimately more compute expenditure.
dbt Fusion directly solves these limitations by introducing a cost-aware, metadata-driven transformation engine that can analyze, estimate, and prevent unnecessary warehouse costs before they reach production

How dbt Fusion Reduces Cost on Snowflake & BigQuery
dbt Fusion delivers cost efficiency through a combination of metadata awareness, compile-time validation, and warehouse-optimized orchestration. Below is an in-depth breakdown of the eight major cost-saving mechanisms and how they work in real-world Snowflake and BigQuery environments.

1. Cost-Aware Compilation (The Fundamental Shift)
The Fusion Engine performs deep inspection of each model before it reaches the warehouse, analyzing:
- estimated warehouse cost
- expected scan volume
- materialization impact
- downstream computational cost
- the effect of lineage dependencies
This is a major shift from dbt Core, where cost consequences were only visible after execution.
Example:
Before Fusion:
An “incremental” model silently rebuilds a 400M-row table because its filter was incorrect.
Outcome: A daily warehouse cost spike (e.g., $500/day on Snowflake).
With Fusion:
The engine warns:
“This incremental model will scan 400M rows. Estimated cost: high.”
Instead of discovering the mistake in a billing report, developers see it during development, preventing unnecessary compute consumption.
This is the first time dbt has provided cost intelligence at development time, not after the fact.
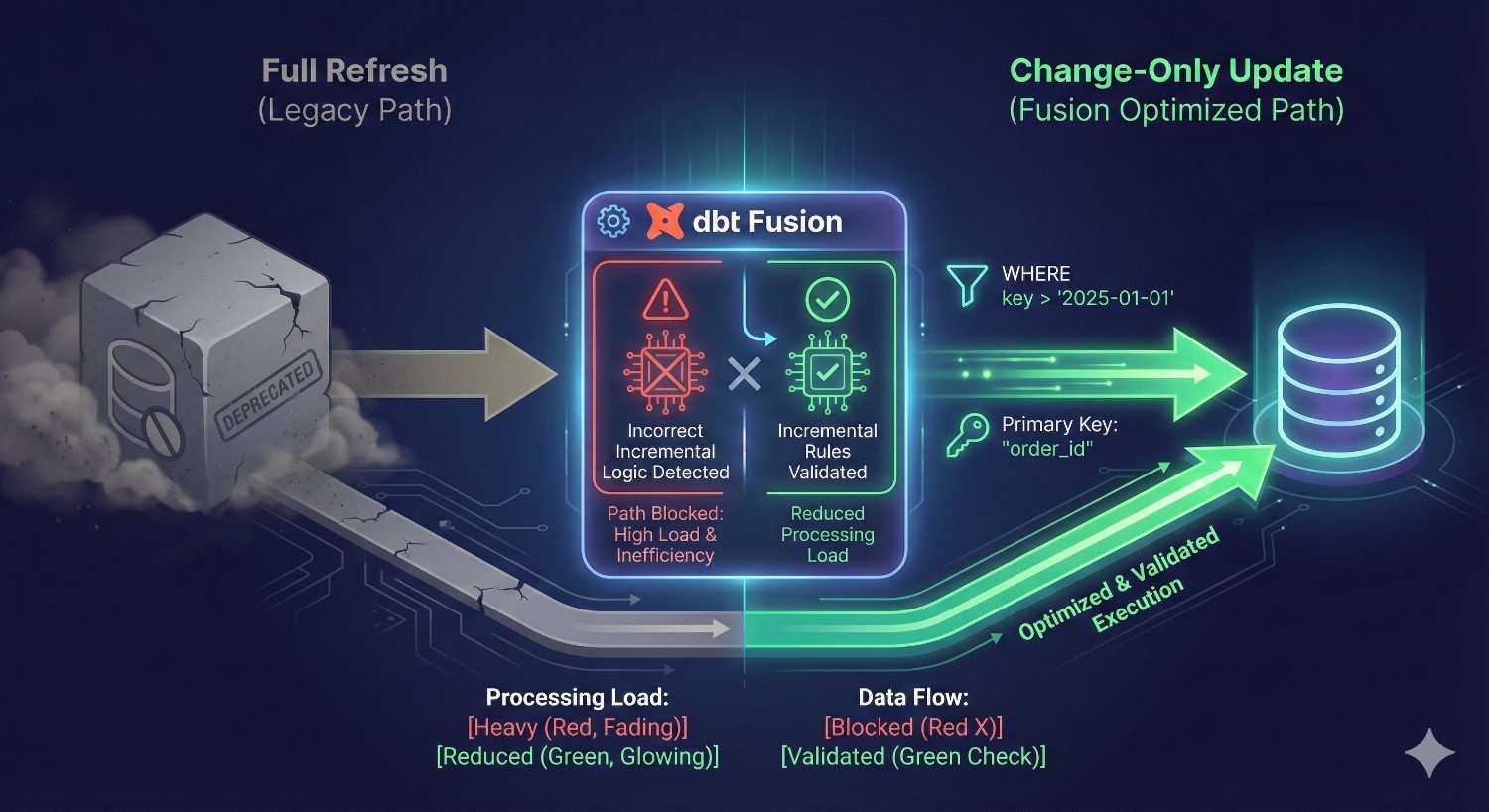
2. Smarter Incremental Logic and Change-Aware Processing
Incorrect incremental logic is one of the most common — and expensive — failure points in dbt Core.
Frequent issues include:
- missing or incorrect unique_key
- filters in is_incremental() that do not restrict the dataset
- schema mismatches that cause silent full refreshes
- upstream changes triggering full downstream rebuilds
dbt Fusion introduces validation and metadata-driven incremental execution that includes:
- dependency-aware incremental execution
- compile-time verification of incremental filters
- change-only updates (only modified rows are processed)
- schema change detection to prevent accidental full rebuilds
Result:
Transformations run only when needed and only where data changed, cutting unnecessary warehouse processing.
Most teams observe measurable reductions in compute spend within days of enabling these checks.
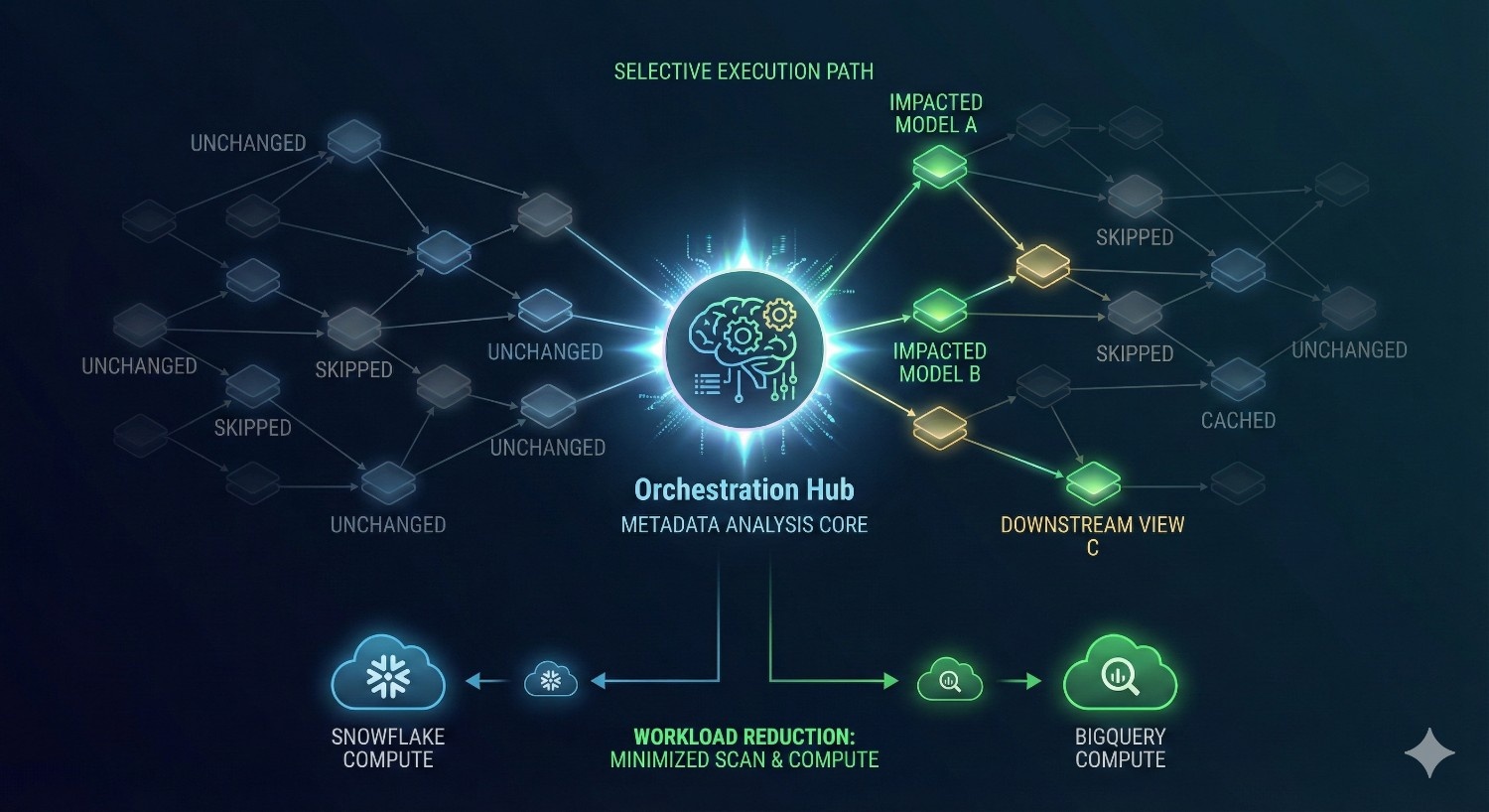
3. Metadata-Aware Orchestration With Smarter Run Decisions
dbt Core orchestrates execution based purely on DAG dependencies. If one upstream table changes, all downstream models in the path may run — whether or not they require recomputation.
dbt Fusion’s orchestrator analyzes metadata to decide:
- which models need to run
- which models can be skipped
- whether a downstream model is actually affected by the upstream change
- whether a cached version can be reused
- whether an incremental run is sufficient
Snowflake example:
A production model depends on 12 upstream tables, but only one table changed.
- dbt Core → triggers the entire subtree
- dbt Fusion → selectively runs only the impacted models
In mature pipelines, selective execution alone reduces compute usage by 30–70%.
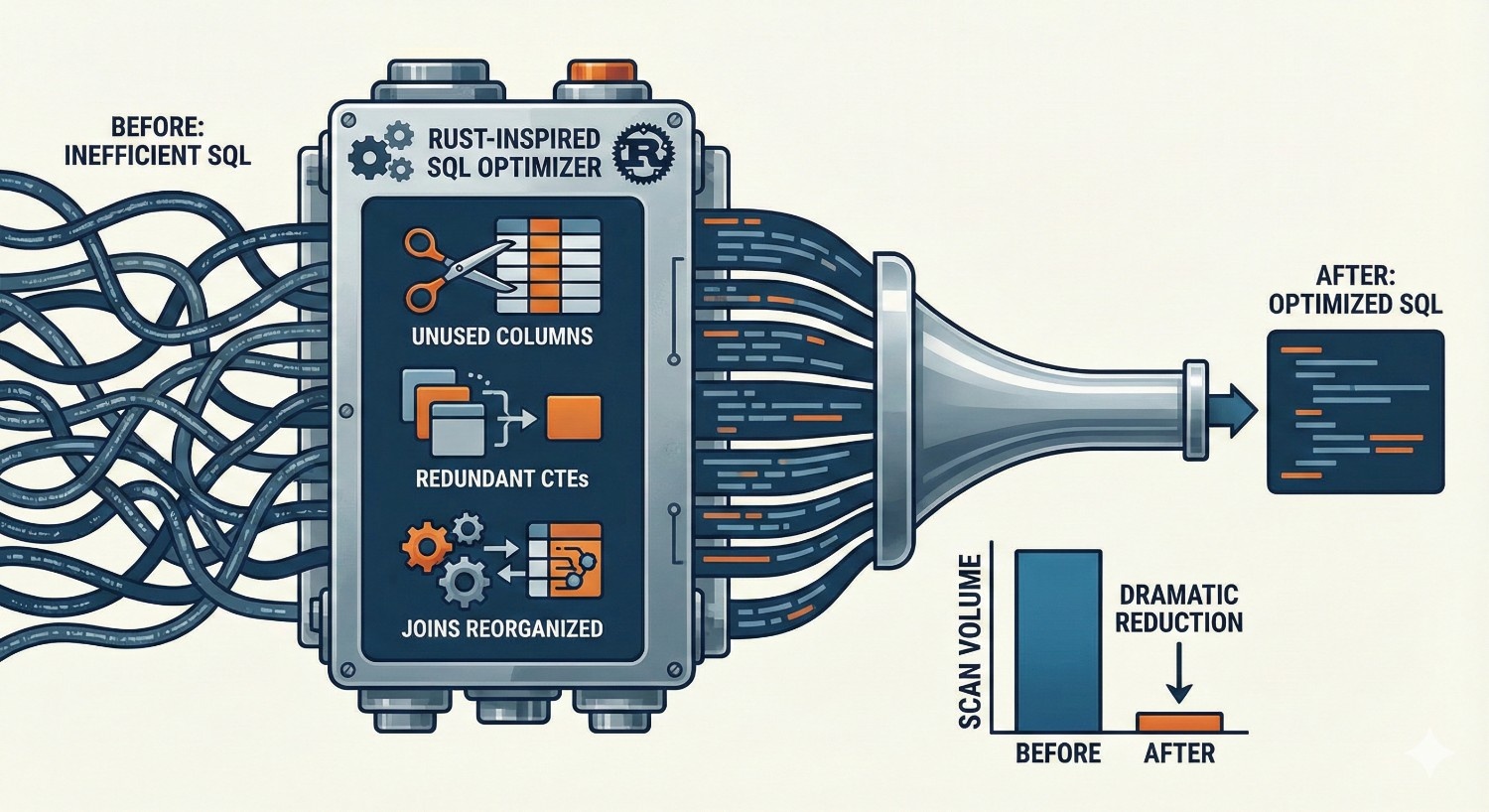
4. Query Efficiency Improvements Through the Rust Engine
The Fusion Engine performs SQL-level optimizations impossible in dbt Core’s Python-based compiler. These include:
- advanced SQL parsing and pruning
- intelligent join reordering
- elimination of redundant CTE expansions
- column-level pruning for downstream queries
- partial materialization planning
- improved warehouse warm-up patterns
The resulting SQL is:
- more efficient
- less redundant
- cheaper to run
- optimized for warehouse architecture
Impact on BigQuery:
BigQuery charges based on the amount of data scanned.
Fusion reduces scan volume with:
- partition-aware pruning
- unnecessary column elimination
- optimized filtering
- reduced intermediate table scans
Even minor SQL improvements translate directly into lower slot usage or on-demand costs.
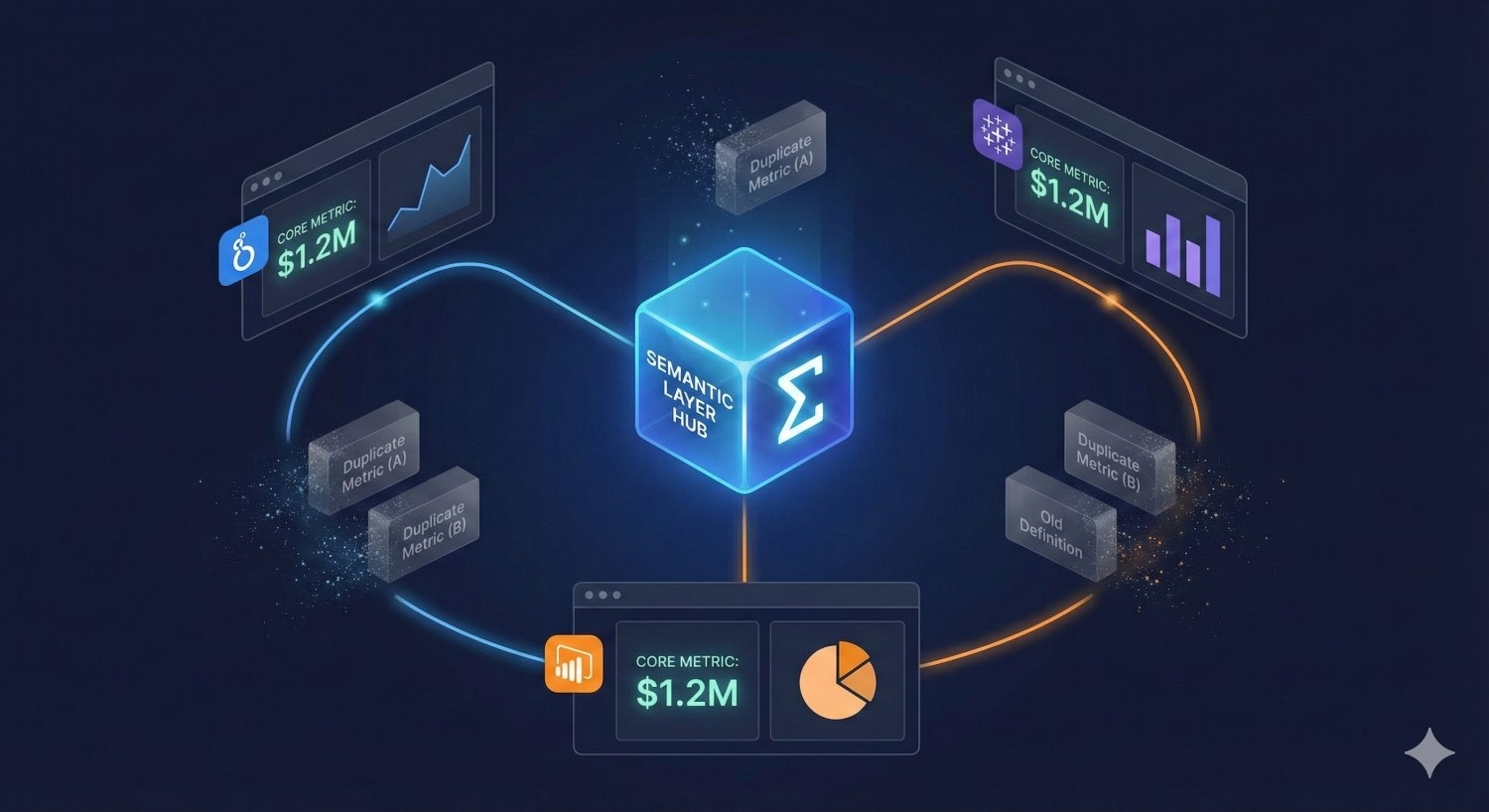
5. Unified Semantic Layer Reduces Duplicate Logic and Redundant Queries
One of the biggest sources of Snowflake/BigQuery cost inflation is metric duplication.
Different teams and BI tools compute the same metric in slightly different ways, causing:
- repeated scans of fact tables
- duplicated transformations
- unnecessary aggregation work
- inconsistent business logic
Fusion’s semantic layer centralizes metric definitions and pushes optimized queries directly into BI tools.
This eliminates:
- duplicate metric queries
- repeated calculations across dashboards
- unnecessary table scans
- redundant warehouse loads
With a shared semantic layer, teams no longer run 10 different versions of the same KPI.
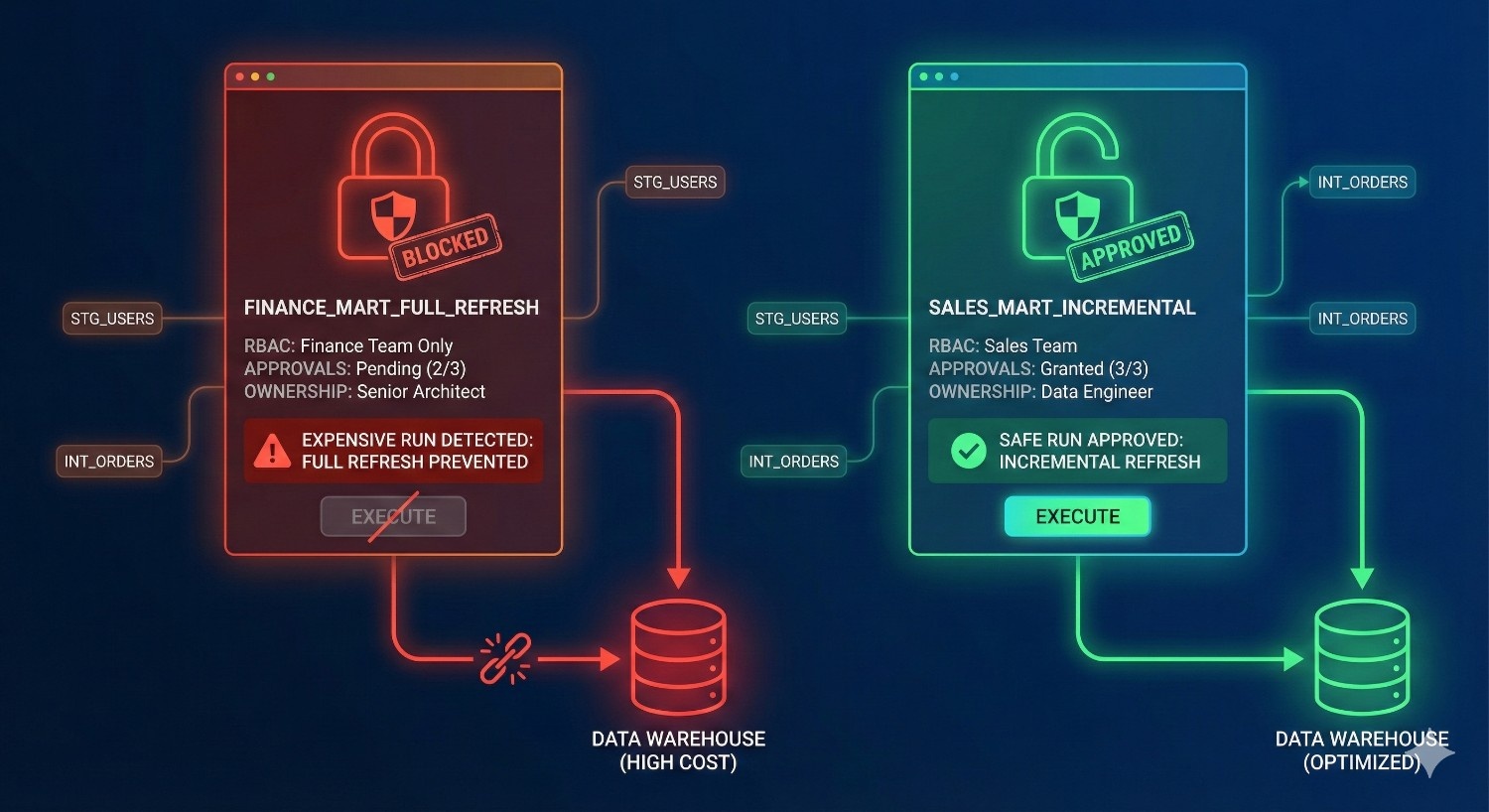
6. Model Ownership, Governance, and Controlled Execution
Many warehouse cost spikes come from human error:
- accidental full refreshes
- unapproved changes to materializations
- models running too frequently
- untested logic deployed directly to production
- developers manipulating schedules without oversight
Fusion introduces:
- model ownership
- approval workflows
- deployment gates
- PR-based semantic changes
- run accountability and lineage impact previews
These guardrails reduce unexpected high-cost operations caused by both junior and senior contributors.
A governed environment is naturally a lower-cost environment.
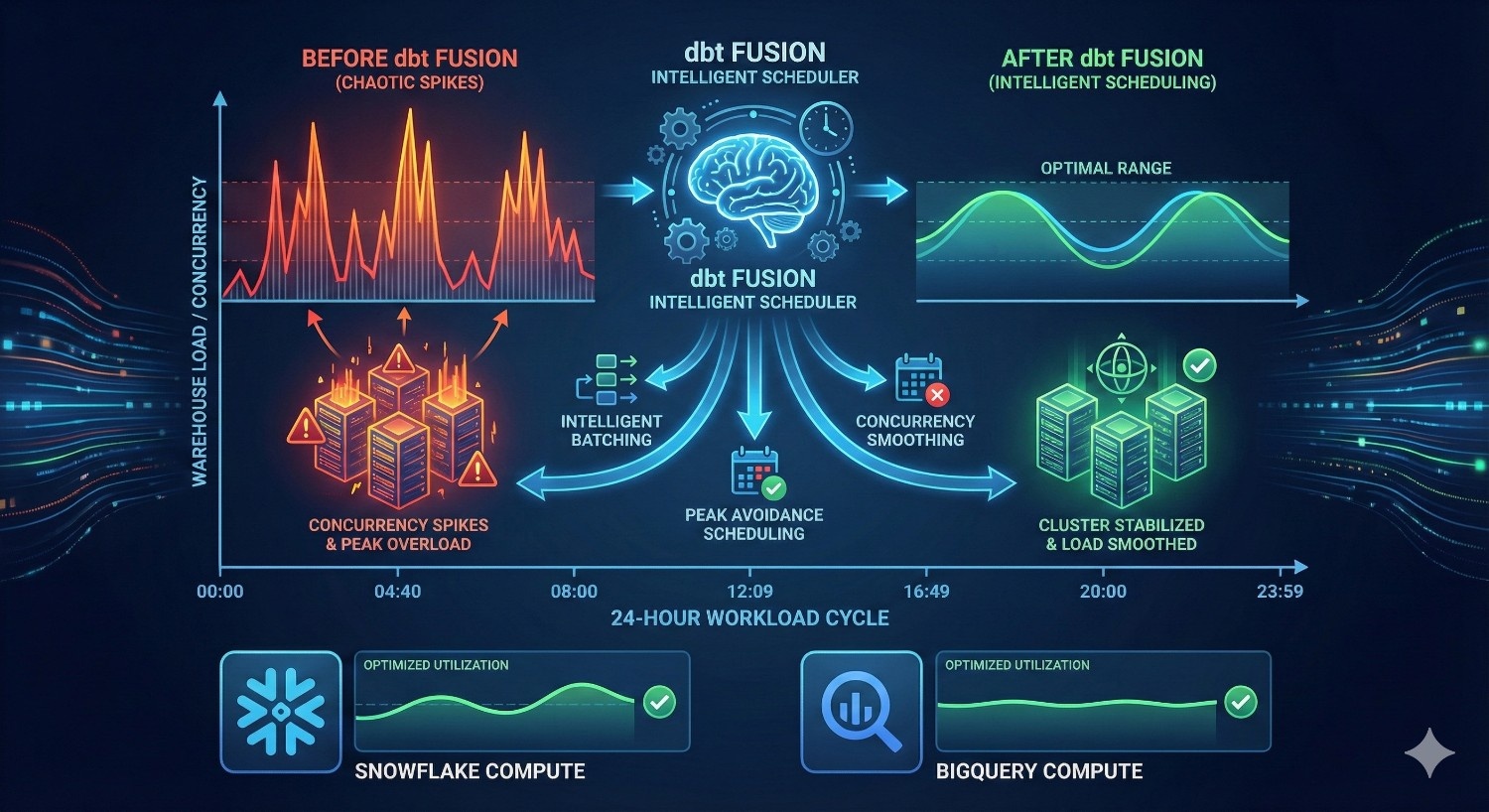
7. Warehouse-Aware Scheduling and Intelligent Workload Management
dbt Fusion uses metadata and warehouse signals to optimize when transformations run. The scheduler can:
- run incremental models more often than full ones
- avoid full rebuilds during peak warehouse load
- queue workloads to prevent multi-cluster auto-scaling
- batch related models to reuse cached data
- prevent overlapping runs that drive peak concurrency costs
Snowflake example:
Fusion can prevent triggering multiple XL warehouses during busy hours, avoiding unintended auto-scaling events.
BigQuery example:
Fusion helps avoid slot contention during heavy, parallelized model execution.
This leads to smoother pipelines and more predictable, controlled spending.
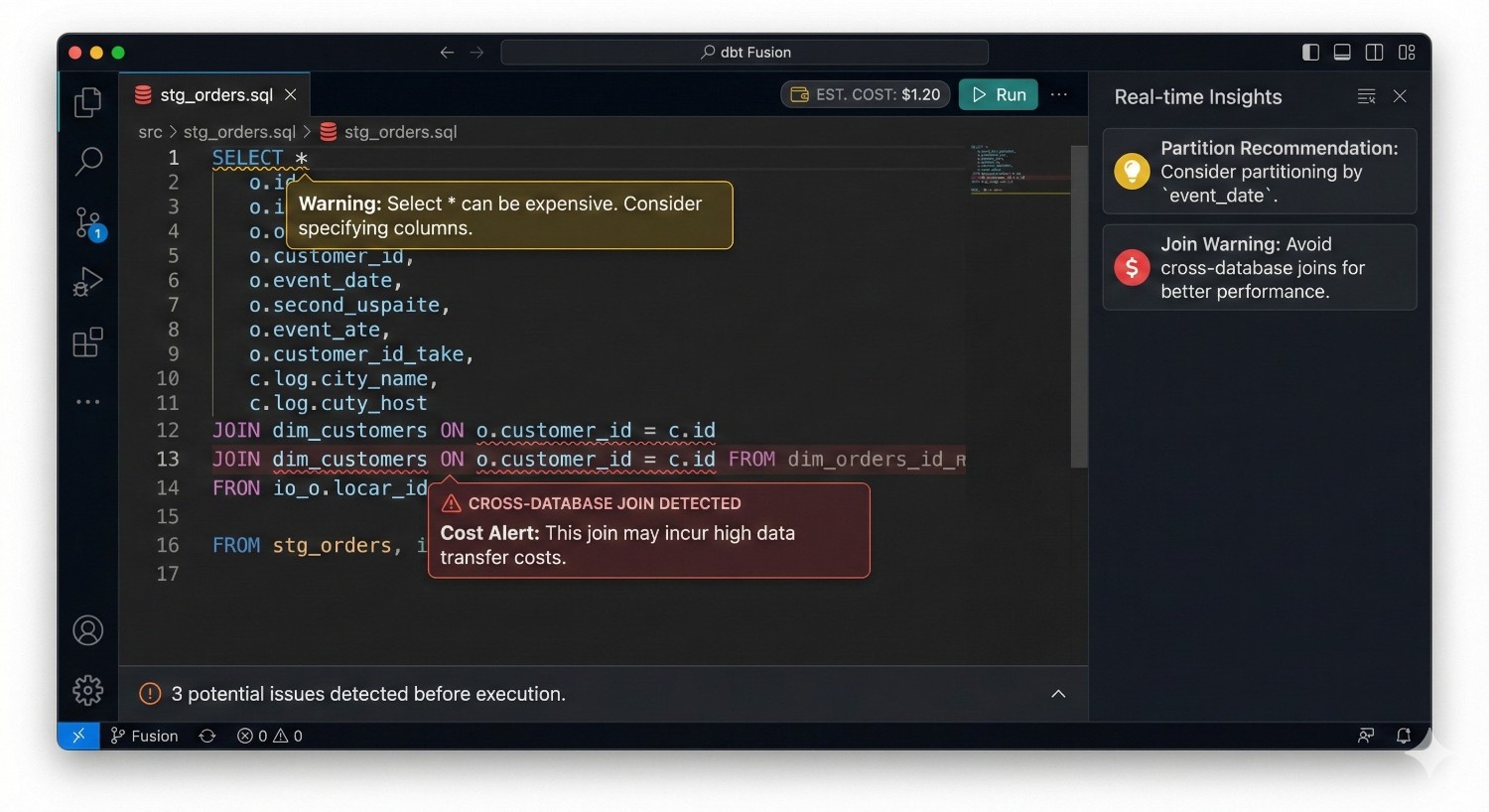
8. Developer Feedback Loops That Prevent Expensive Mistakes
Fusion’s IDE provides:
- real-time SQL validation
- immediate cost estimation
- warnings for inefficient query patterns
- schema-change detection
- hints for partitioning and filtering optimization
This reduces the likelihood of:
- Cartesian joins
- full scans on massive fact tables
- non-partitioned filters
- poorly structured incremental logic
- unnecessary CTE expansion
Instead of learning through an expensive production run, developers receive instant feedback during development.
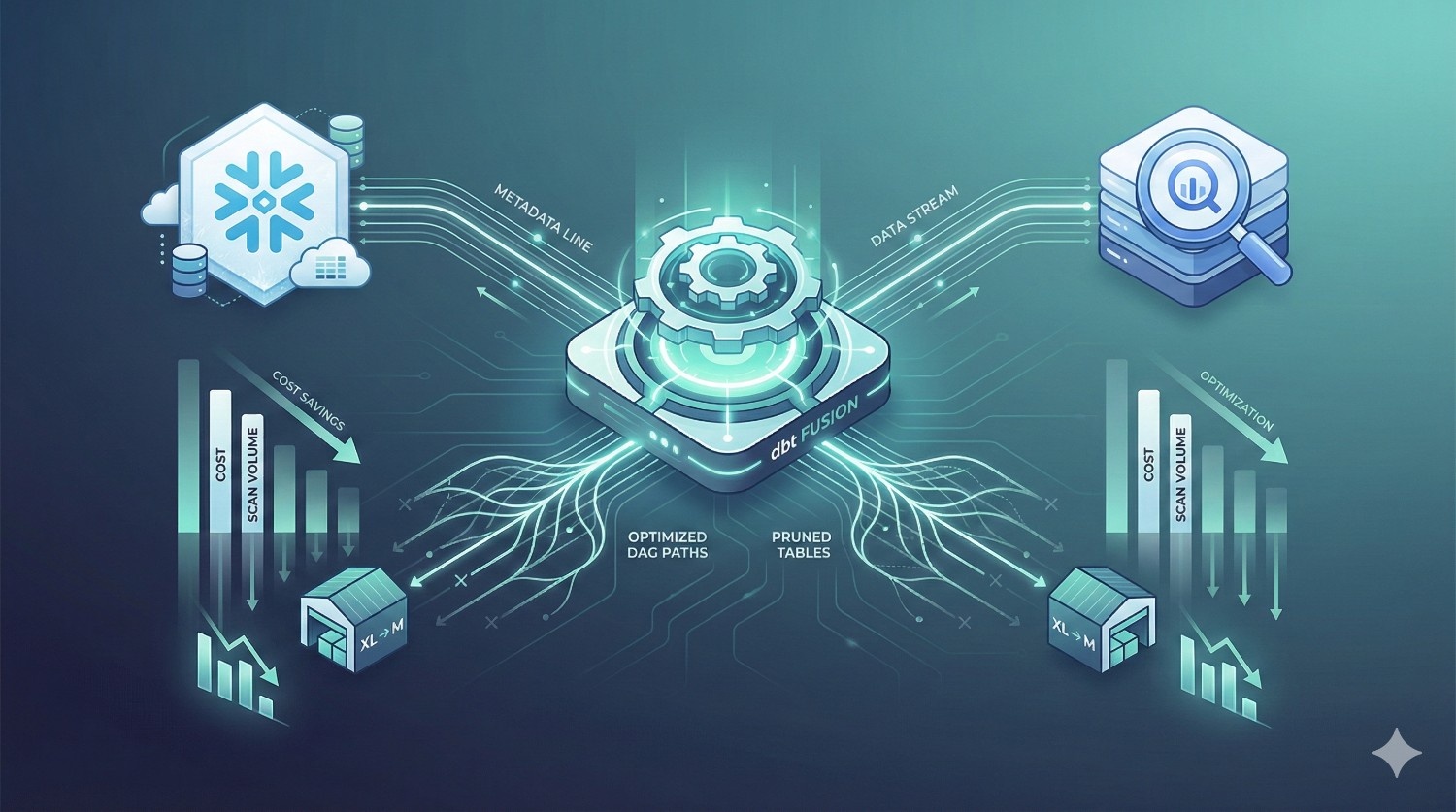
Real-World Cost Savings with dbt Fusion
dbt Fusion delivers measurable reductions in warehouse compute spending by combining metadata-aware orchestration, cost-intelligent compilation, and optimized SQL generation. Below are real patterns observed across DataPrism client environments and industry case studies.
Snowflake Cost Savings
Snowflake pricing is heavily influenced by warehouse size, credit consumption, auto-scaling, and the number of full or partial table scans. dbt Fusion reduces compute waste by preventing unnecessary runs, improving incremental logic, and reducing lineage bloat.
The following table illustrates typical cost reductions seen when teams migrate from dbt Core to dbt Fusion:
|
Problem
|
Typical Cost With dbt Core
|
Cost With dbt Fusion
|
Explanation
|
|---|---|---|---|
|
Unoptimized incremental refresh
|
$300/day
|
$30/day
|
Fusion validates incremental filters and prevents silent full scans.
|
|
Costly full DAG rebuild
|
$1,200/run
|
$250/run
|
Metadata-aware orchestration prevents cascading full rebuilds.
|
|
Duplicate BI metric queries
|
~40% compute waste
|
Eliminated
|
Semantic layer centralizes metric logic across BI tools.
|
|
Peak-hour scheduling overload
|
Auto-scale to 4XL
|
Runs on M or L
|
Fusion schedules workload more intelligently to avoid unnecessary scaling.
|
Expected savings:
Most organizations achieve 30–60% reduction in Snowflake compute cost within the first quarter after adopting dbt Fusion.
This improvement is driven by:
- avoiding unnecessary full refreshes
- reducing large-table scans
- minimizing overlapping runs
- eliminating repeated metric calculations
- optimizing heavy joins and filters before execution
BigQuery Cost Savings
BigQuery’s cost model is based on data scanned, not runtime, making SQL efficiency and pruning crucial. dbt Fusion’s Rust engine and metadata framework significantly reduce scan volume.
Fusion optimizes:
- partition pruning
- column-level filtering
- SQL generation for fewer scanned bytes
- avoiding redundant table scans
- preventing duplicated metric calculations
- eliminating unnecessary ad-hoc transformations
Teams commonly observe:
- fewer large fact-table scans
- reduced slot contention
- improved partition and clustering utilization
- more predictable monthly spending
Expected savings:
On average, dbt Fusion leads to a 25–50% reduction in BigQuery data scanned per month, depending on pipeline maturity and data model size.
For organizations with high-volume reporting workloads, savings can be even higher when combined with:
- semantic layer adoption
- optimized incremental logic
- consolidated BI metric queries
- metadata-aware run decisions

Who Benefits the Most?
While dbt Fusion provides value to any team using dbt Core today, certain environments see disproportionately large improvements in both performance and compute efficiency. The following types of organizations gain the most from Fusion’s cost-aware engine and metadata-driven orchestration.
High-Volume ETL/ELT Workflows
Teams processing large fact tables, event streams, or high-frequency refreshes experience immediate cost reductions. Fusion prevents unnecessary scans, controls incremental logic, and optimizes SQL for warehouse efficiency.
Daily or Hourly Incremental Pipelines
Frequent updates amplify the impact of poor incremental logic. Fusion’s compile-time validation and dependency-aware execution drastically reduce unnecessary full refreshes and high-volume incremental runs.
Multi-BI Environments (Looker, Sigma, Tableau, Mode, Hex)
Organizations with multiple BI tools often pay for the same metric calculations several times. Fusion’s semantic layer centralizes metric definitions, eliminating redundant queries and reducing BI-driven warehouse load.
Large Snowflake & BigQuery Installations
Enterprises running XL/2XL Snowflake warehouses or consuming large BigQuery scan volumes see significant improvements through cost estimation, SQL pruning, and workload-aware scheduling.
Multi-Team Analytics Organizations
Fusion’s governance model—RBAC, model ownership, environment isolation, and approval workflows—reduces accidental high-cost operations caused by uncoordinated development across teams.
Heavy Ad-Hoc Analysis Environments
Teams conducting frequent exploratory analysis often generate repeated, inconsistent, or inefficient queries. The semantic layer and optimized SQL generation help minimize unnecessary scans.
Companies Without Strict Governance
Organizations lacking structure around model ownership, deployment approvals, or warehouse scheduling often suffer uncontrolled cost growth. Fusion’s governance and metadata framework introduces discipline without slowing development.
Is dbt Fusion Worth the Investment?
For many organizations, the financial justification for dbt Fusion is straightforward. When evaluated purely through the lens of Snowflake and BigQuery cost savings, Fusion often becomes a net-positive investment within months.
If your Snowflake bill exceeds $10,000 per month
Fusion’s cost-aware compilation, incremental validation, and metadata-driven orchestration typically reduce compute spend by 30–60 percent. At this scale, those savings alone outweigh the licensing cost.
If your BigQuery environment scans more than 20 TB per month
Fusion’s SQL pruning, partition-aware optimization, and semantic-layer consolidation materially reduce scanned bytes. This translates into predictable and recurring savings that consistently exceed Fusion’s platform fees.
If your team includes more than five analytics engineers
Beyond cost control, Fusion dramatically improves development velocity through:
- live previews
- compile-time error detection
- hybrid IDE workflows
- environment isolation
- model ownership and RBAC
This reduces debugging time, failed deployments, and operational overhead—delivering measurable productivity gains.
Bottom line
dbt Fusion is not an added expense.
For most organizations, it becomes a cost-reduction mechanism, a productivity accelerator, and a governance framework that eliminates the inefficiencies and unknowns typically associated with scaling dbt Core.
Fusion consistently pays for itself—often within a single billing cycle.
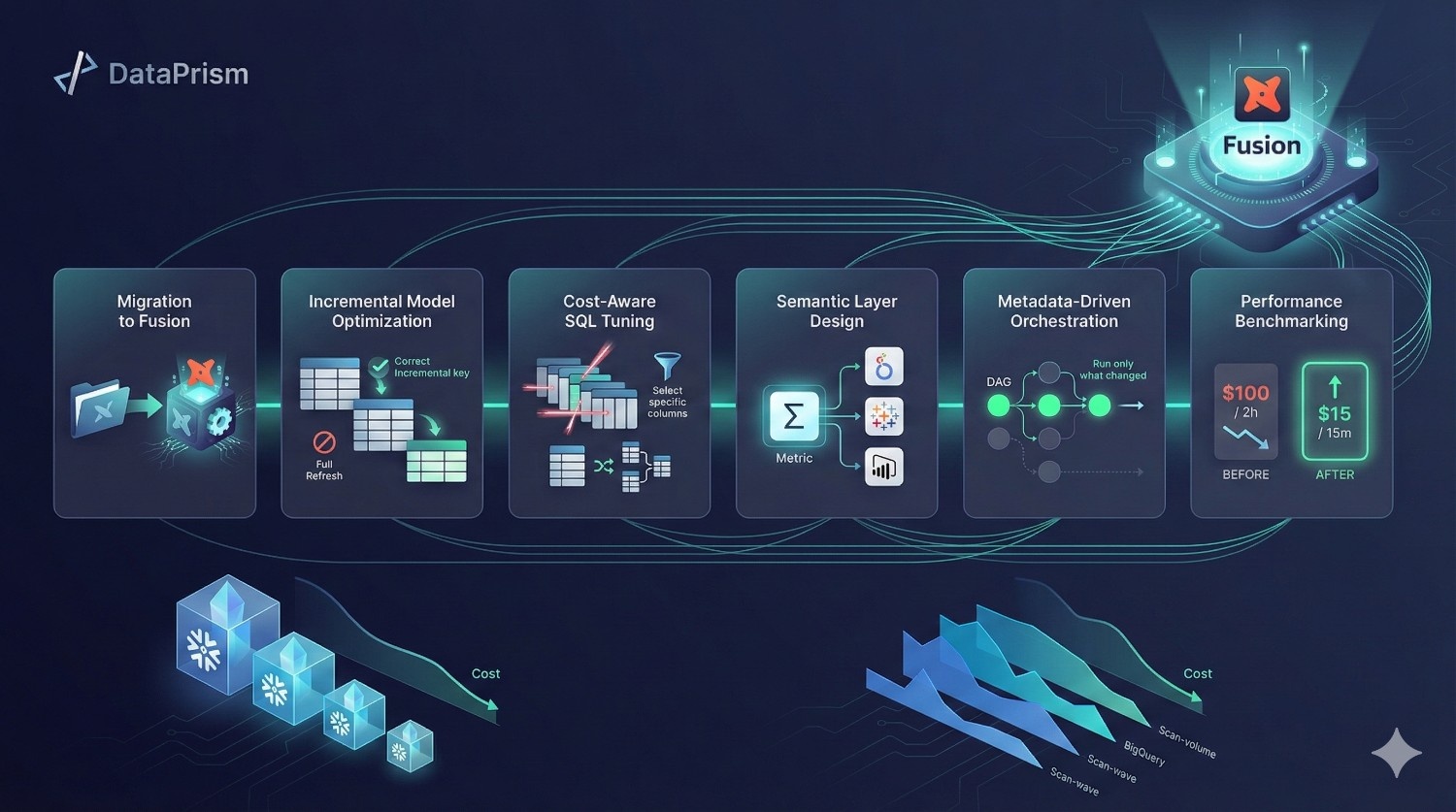
How DataPrism Helps Reduce Snowflake & BigQuery Cost with dbt Fusion
Adopting dbt Fusion is only part of the equation. The real value comes from implementing it with the right architectural patterns, governance practices, and warehouse optimizations. DataPrism works directly with engineering and analytics teams to ensure Fusion becomes a cost-reduction engine rather than just another tool in the stack.
Migration from dbt Core to dbt Fusion
We guide organizations through a structured migration process, ensuring that models, lineage, tests, and environments transition cleanly into Fusion’s metadata-driven framework. This includes validating incremental logic, verifying semantic definitions, and configuring governed environments.
Optimization of Incremental Models
Poorly designed incremental logic is one of the primary sources of warehouse overspending.
DataPrism:
- validates incremental filters
- corrects unique keys
- ensures change-only processing
- prevents unintended full refreshes
This often results in immediate reductions in Snowflake credits and BigQuery scan volume.
Cost-Aware SQL and Warehouse Optimization
We refactor legacy SQL into cost-efficient patterns that leverage:
- partition pruning
- column filtering
- clustering and micro-partition principles
- optimized join strategies
- reduced intermediate scans
Combined with Fusion’s Rust engine, these improvements have a measurable impact on compute consumption.
Design of Semantic Layers That Reduce Warehouse Load
The semantic layer prevents BI tools and analysts from generating redundant or inconsistent queries.
DataPrism helps teams:
- centralize metric definitions
- eliminate duplication across dashboards
- reduce repeated fact-table scans
- streamline downstream transformations
This removes a major driver of unnecessary warehouse workload.
Metadata-Driven Orchestration and Scheduling
We configure dbt Fusion’s orchestrator to make intelligent decisions about:
- which models must run
- which runs can be safely skipped
- how to avoid cascading rebuilds
- when to schedule compute-heavy models
- how to balance workloads against warehouse utilization
This approach reduces compute volatility and delivers more predictable cost patterns.
Warehouse Bottleneck Resolution
Many teams face issues such as:
- slow-running models
- repeated stalls during peak hours
- inefficient DAG structures
- heavy joins causing Snowflake or BigQuery throttling
DataPrism identifies and resolves these bottlenecks using both warehouse diagnostics and Fusion metadata.
Performance Benchmarking and Cost Modeling
We run before-and-after benchmarks to quantify improvements in:
- runtime
- scanned data
- warehouse credit consumption
- DAG depth and complexity
- pipeline reliability
These insights help organizations understand where cost improvements originate and how to sustain them.
Our Value Proposition
DataPrism does not simply implement dbt Fusion.
We ensure that the combination of Fusion + optimized SQL + semantic governance delivers 30–60 percent lower warehouse cost while dramatically improving pipeline reliability and developer efficiency.

Conclusion
dbt Fusion is more than an upgraded engine — it is a cost-efficiency accelerator for modern data teams. By merging Rust-powered compilation, metadata-aware orchestration, semantic caching, and cost-intelligent SQL generation, Fusion provides the visibility and control that organizations have historically lacked in Snowflake and BigQuery environments.
Teams adopting Fusion see immediate improvements in pipeline performance, governance, collaboration, and, most importantly, warehouse spend. For organizations looking to streamline operations, reduce compute cost, and standardize business logic across the analytics lifecycle, dbt Fusion represents one of the most strategic and high-impact upgrades available in 2025.
If your priority is to deliver:
- faster, more reliable pipelines
- lower Snowflake or BigQuery bills
- consistent, reusable metrics
- governed development workflows
- smooth multi-team collaboration
dbt Fusion is the right next step in your analytics engineering evolution.
Frequently Asked Questions (FAQs)
No. dbt Fusion extends dbt Core. Core remains the foundation for SQL transformation logic, while Fusion adds orchestration, governance, semantic modeling, cost awareness, and a hybrid IDE.
Yes. Even teams with 3–5 engineers typically reduce Snowflake or BigQuery spend through better incremental logic, optimized SQL, and improved orchestration. However, the ROI becomes even stronger for medium and large teams.
Fusion reduces Snowflake spend by:
- preventing unnecessary full refreshes
- optimizing SQL to reduce micro-partition scans
- orchestrating workloads to avoid auto-scaling
- centralizing metric queries across BI tools
- validating incremental logic before execution
These improvements often cut Snowflake compute cost by 30–60 percent.
Fusion optimizes BigQuery workloads through:
- partition pruning
- column-level filtering
- reduced scan volume
- semantic-layer elimination of duplicate queries
- optimized SQL generation via the Rust engine
Teams commonly see 25–50 percent reductions in scanned bytes.
Yes. Metric duplication is one of the largest hidden cost drivers in both Snowflake and BigQuery. Fusion’s semantic layer ensures metrics are calculated once, cached, and reused everywhere — significantly reducing redundant workloads.
Yes. Fusion provides:
- cost estimates before execution
- warnings for inefficient SQL patterns
- incremental logic validation
- schema-change detection
- live previews in the IDE
This prevents costly full-table scans, cartesian joins, and unnecessary refreshes.
Yes. Fusion supports migration of existing dbt Core projects with minimal restructuring. Most teams migrate in a few days.
For most organizations, yes. If your Snowflake bill exceeds $10,000 per month or your BigQuery scan volume exceeds 20 TB per month, Fusion typically pays for itself through reduced compute.
Not necessarily. Fusion can orchestrate transformations independently, but it can also integrate with existing schedulers if required. Most teams reduce tool sprawl by consolidating orchestration into Fusion.
Most teams migrate from dbt Core to dbt Fusion in 2–10 days, depending on project size, incremental model complexity, and semantic-layer requirements.
Yes. DataPrism specializes in dbt Fusion migrations, warehouse optimization, semantic layer design, and cost-reduction strategies across Snowflake and BigQuery.