
Introduction
The Problem: Why Legacy Pipeline Tooling Was Cost-Blind
5 Ways the Fusion Engine Drastically Cuts Cloud Spend
The platform delivers cost efficiency through a powerful combination of metadata awareness, compile-time validation, and dynamic orchestration decisions. Below is an in-depth breakdown of the several key mechanisms through which dbt Fusion can help reduce cost in Snowflake and BigQuery environments.
1. Cost-Aware Compilation (Shift-Left Economics)

The engine performs deep inspection of each model before execution. It analyzes estimated scan volume and downstream lineage consequences. Instead of discovering a mistake in a billing report, developers see warnings in their IDE (e.g., "This incremental model will scan 400M rows. Estimated cost: High"), preventing unnecessary compute consumption.
2. Smarter Incremental Logic and Change-Aware Processing
Incorrect incremental logic is one of the most common and expensive failure points in dbt Core.
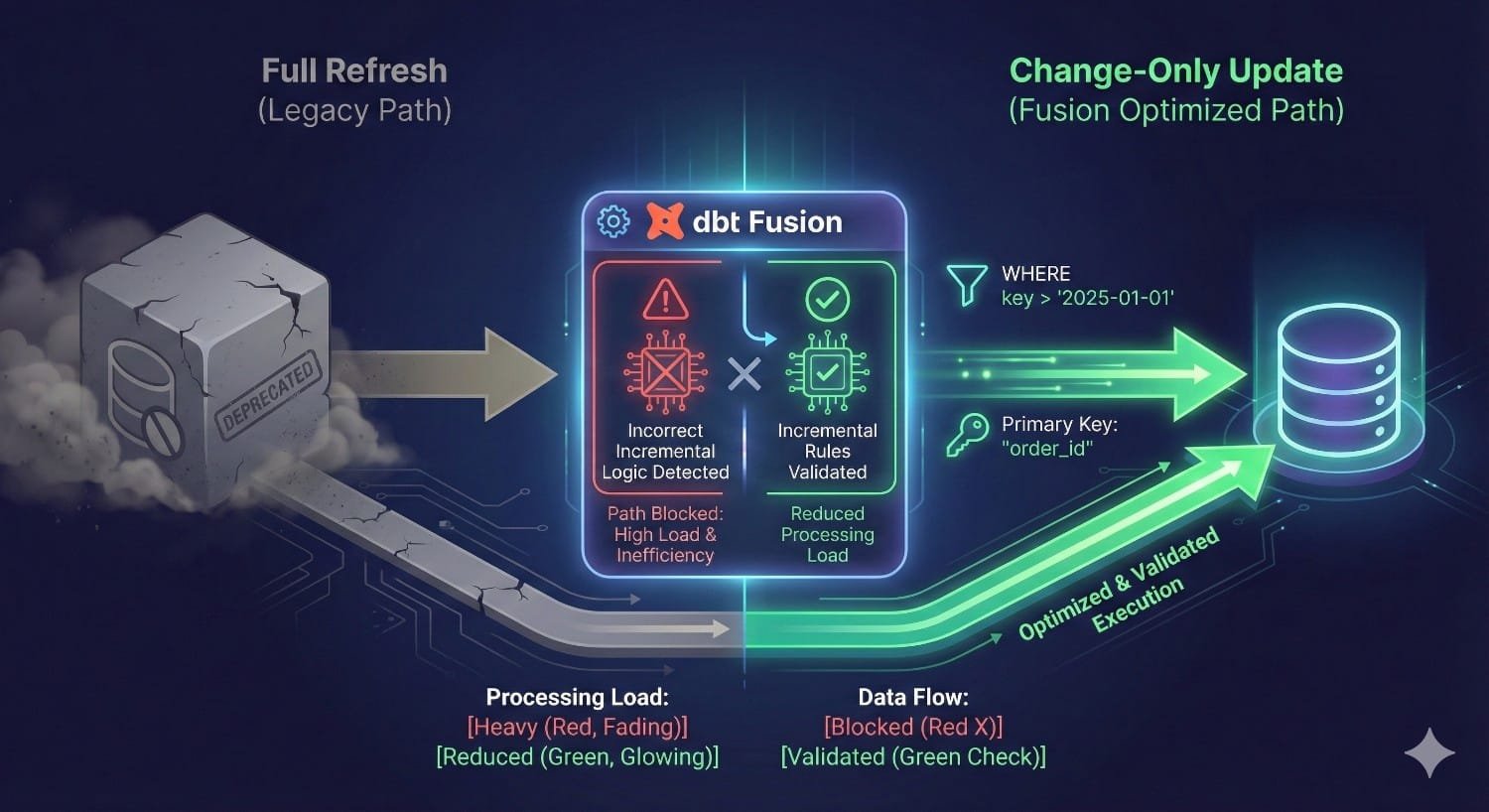
Incorrect incremental logic is incredibly expensive. The Fusion engine introduces dependency-aware incremental execution and schema change detection. By verifying that filters inside is_incremental() actually restrict the dataset, transformations process only modified rows, slashing processing time.
3. Metadata-Aware Orchestration With Smarter Run Decisions
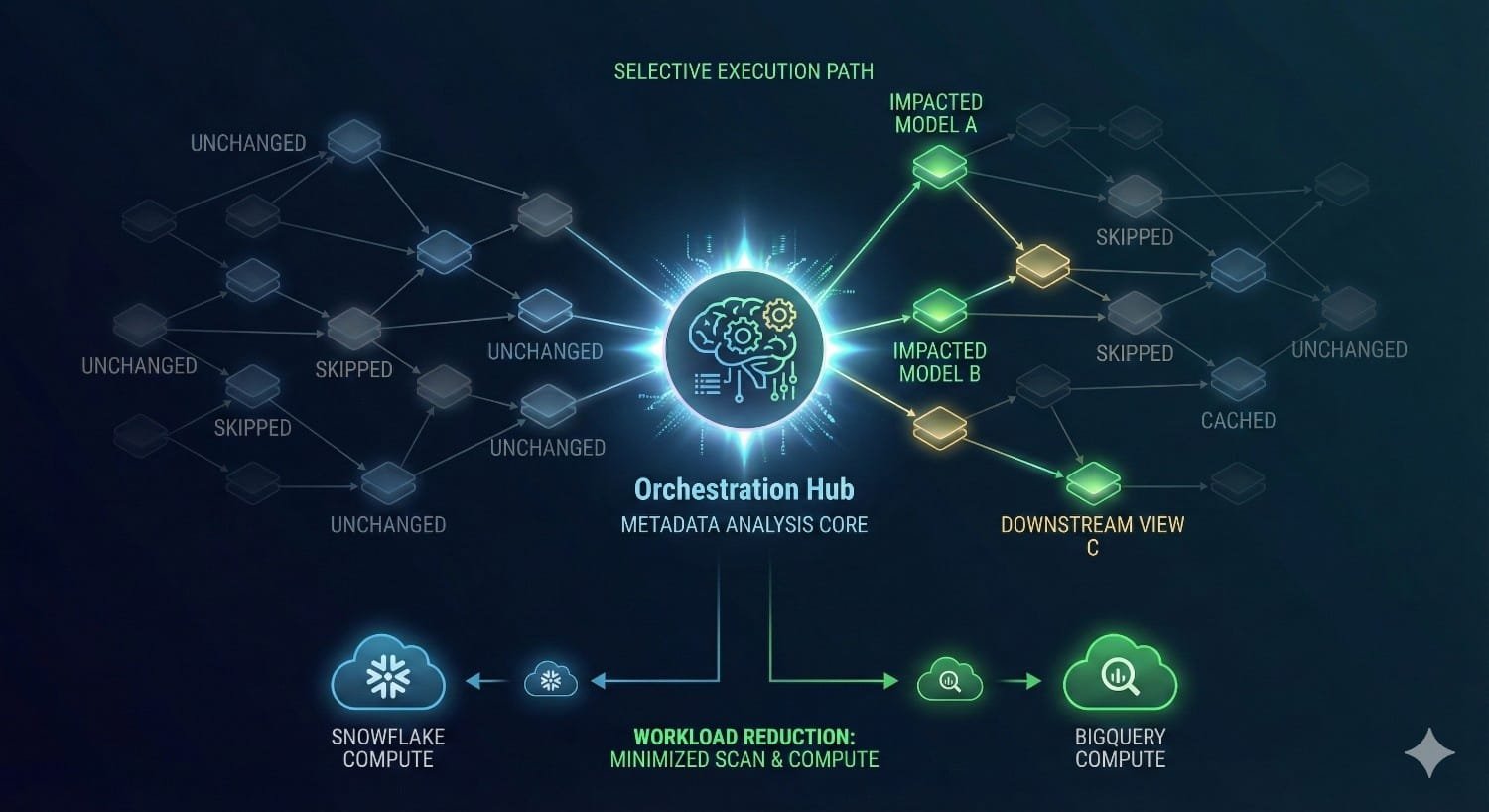
Legacy systems trigger entire subtrees based purely on DAG dependencies. If one upstream table changes, everything downstream runs. Fusion selectively executes only the impacted models based on actual data changes, drastically reducing redundant warehouse load.
Snowflake example:
A production model depends on 12 upstream tables, but only one table changed.
- dbt Core: triggers the entire subtree
- dbt Fusion: selectively runs only the impacted models
In mature pipelines, selective execution alone reduces unnecessary compute usage.
4. Rust-Powered SQL Pruning
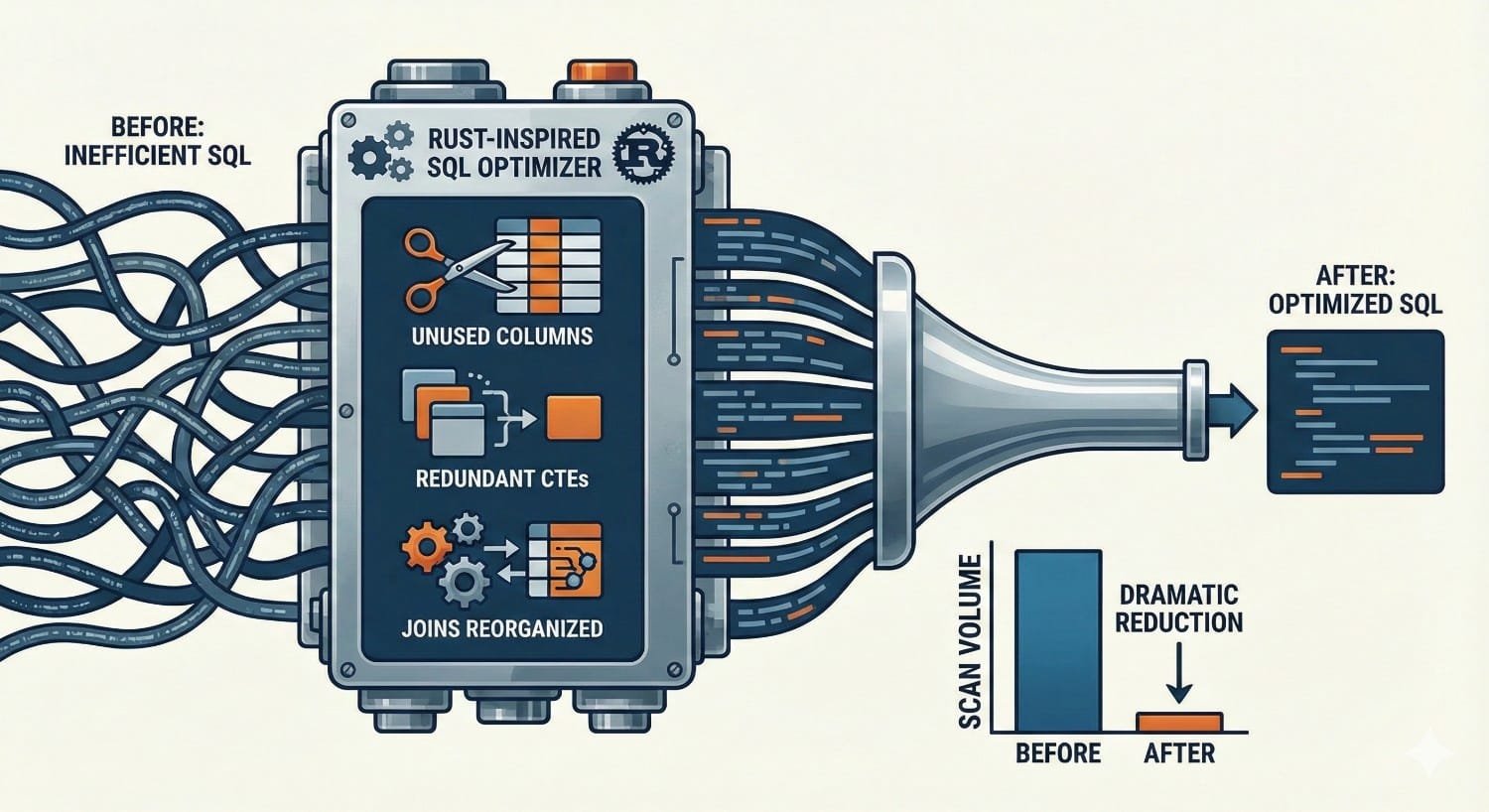
The underlying compiler enables advanced SQL parsing. By eliminating redundant Common Table Expressions (CTEs), pushing down filters, and enforcing partition-aware pruning, the engine generates SQL that requires fewer bytes scanned—a critical factor for reducing Google Cloud BigQuery Pricing.
Impact on BigQuery:
BigQuery charges based on the amount of data scanned. Fusion reduces scan volume with:
- partition-aware pruning
- unnecessary column elimination
- optimized filtering
- reduced intermediate table scans
Even minor SQL improvements translate directly into lower slot usage or on-demand costs.
5. Unified Semantic Layer Deduplication
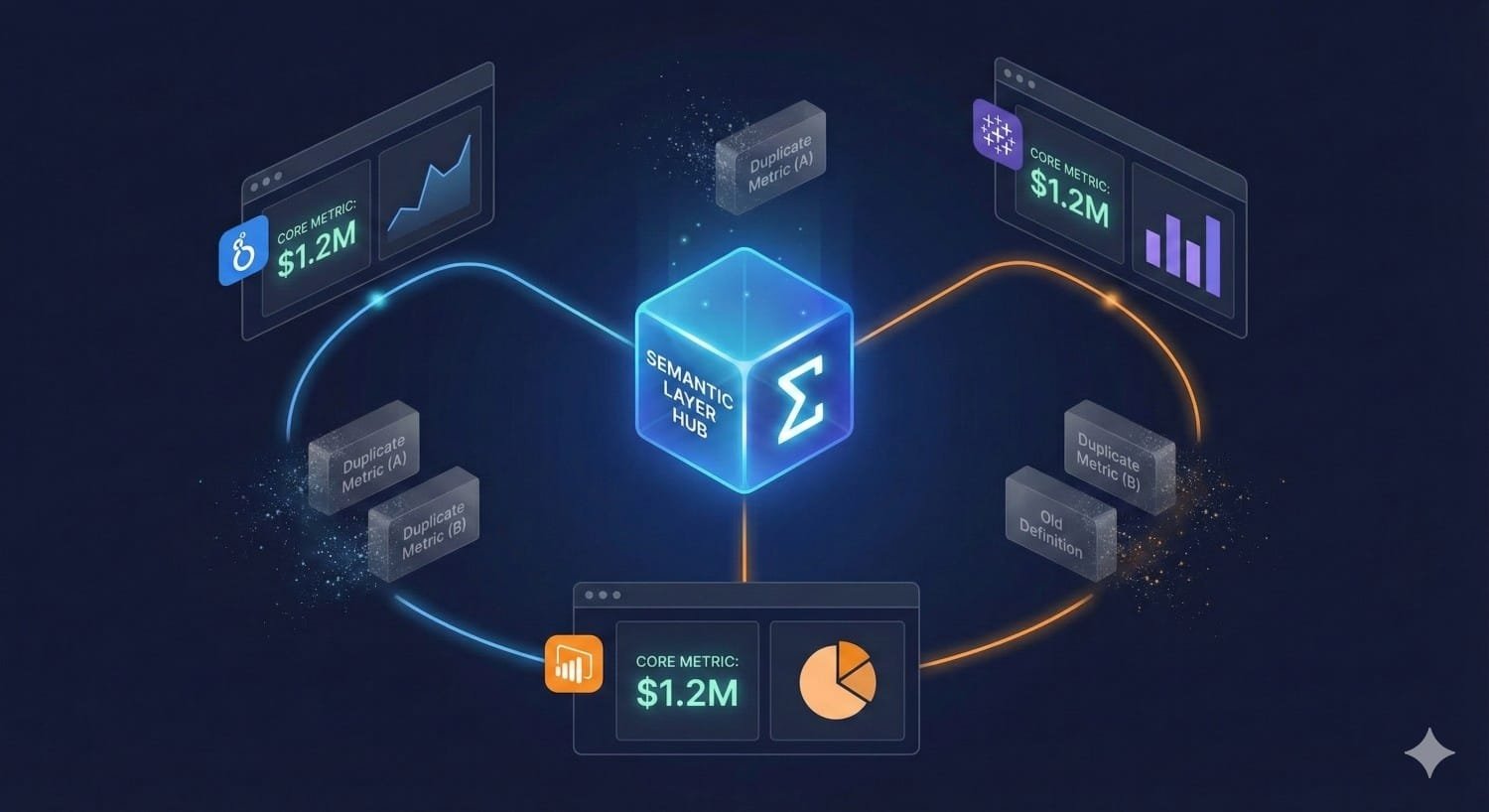
Different business intelligence (BI) tools often compute the identical metric using slightly different logic, causing repeated scans of massive fact tables. Centralizing metrics within the semantic layer eliminates redundant queries and repeated aggregations, lowering continuous warehouse load.
6. Model Ownership, Governance, and Controlled Execution
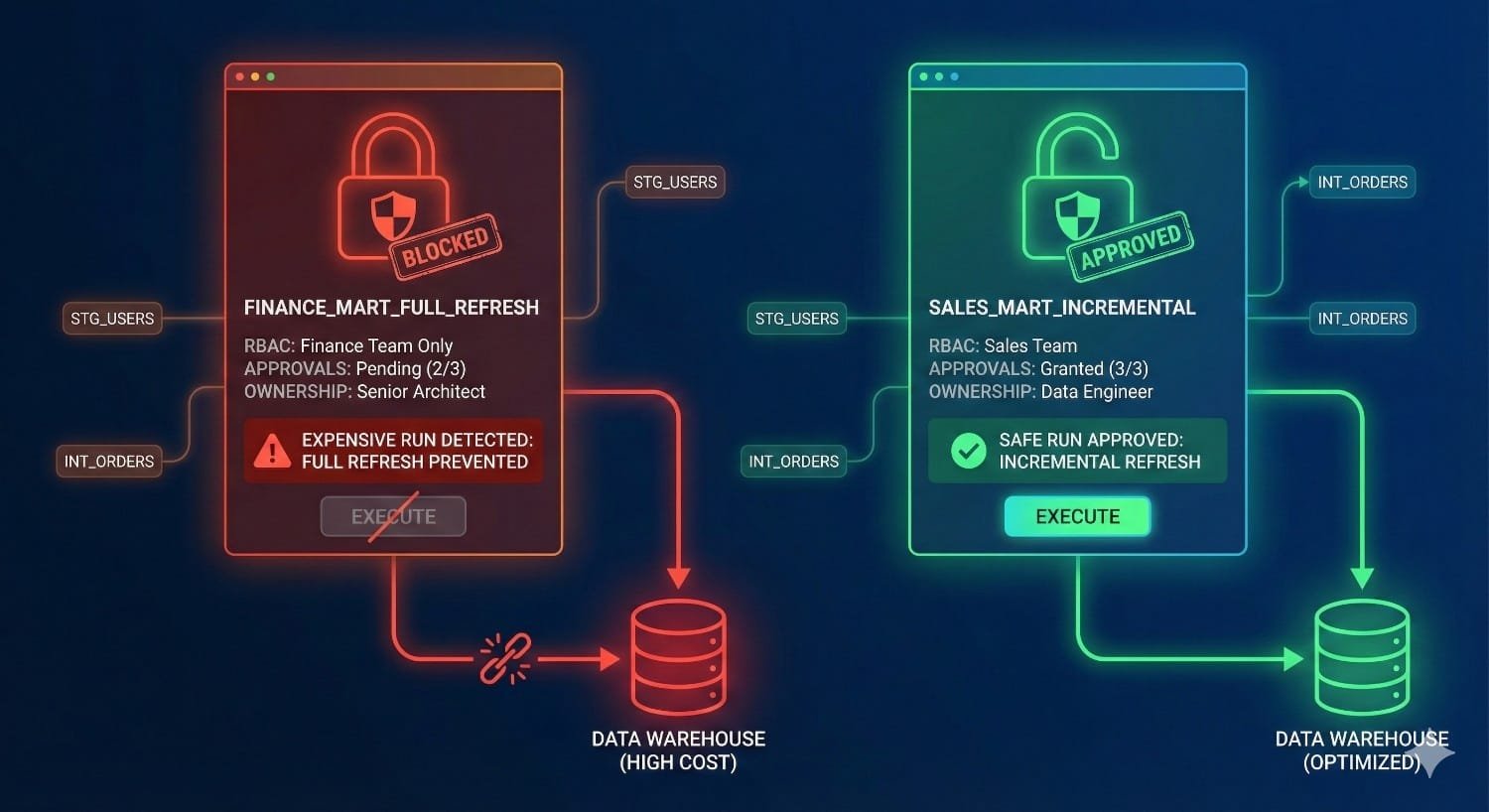
Many warehouse cost spikes come from human errors such as unapproved changes to materializations, accidental full refreshes etc. Fusion helps mitigating these errors by introducing stronger support for:
- model ownership
- approval workflows
- deployment gates
- PR-based semantic changes
- run accountability and lineage impact previews
Optimizing the Medallion Architecture with dbt Fusion
To maximize cost efficiency, technical teams must apply these optimization capabilities directly across the Medallion Architecture layers:
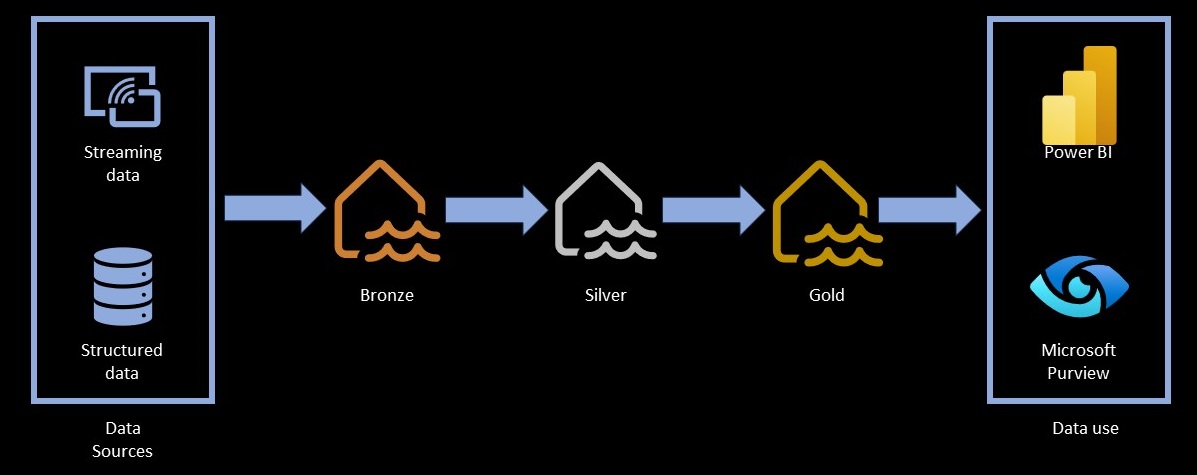
- Bronze Layer (Raw Data): Fusion prevents expensive full scans of raw landing tables by strictly enforcing incremental change-data-capture (CDC) loading limits. It warns or rejects runs that attempt to query unpartitioned raw logs without a timestamp filter.
- Silver Layer (Cleansed & Conformed): During complex joins and deduplication, the compiler’s intelligent pruning ensures that only required columns are passed through memory. This prevents Cartesian joins and excessive spooling to disk on Snowflake Virtual Warehouses.
- Gold Layer (Aggregated Analytics): The semantic layer ensures that downstream tools query pre-aggregated views rather than pounding the Silver layer with heavy, redundant analytical queries during peak business hours.
Real-World Cloud Cost Reduction Matrix
How do these technical upgrades translate into actual dollars saved? Below are representative cost-reduction patterns observed when teams migrate legacy pipelines to metadata-optimized architectures:
|
Operational Inefficiency |
Legacy Pipeline Impact |
Optimized Fusion Architecture |
Engineering Mitigation |
|
Unoptimized Incremental Refreshes |
$300 / day |
$30 / day |
Compile-time validation restricts processing to net-new delta records only. |
|
Cascading Full DAG Rebuilds |
$1,200 / run |
$250 / run |
Metadata-aware orchestration isolates and runs only structurally affected models. |
|
Duplicate BI Metric Queries |
~40% compute waste |
Near Zero |
The semantic layer centralizes logic, caching results across all downstream dashboards. |
|
Peak-Hour Warehouse Scaling |
Forces 4XL auto-scaling |
Stabilizes at Large/XL |
Intelligent workload queues prevent concurrent model overlaps that trigger burst scaling. |
Snowflake Cost Savings: Optimizing Compute Time & Credits
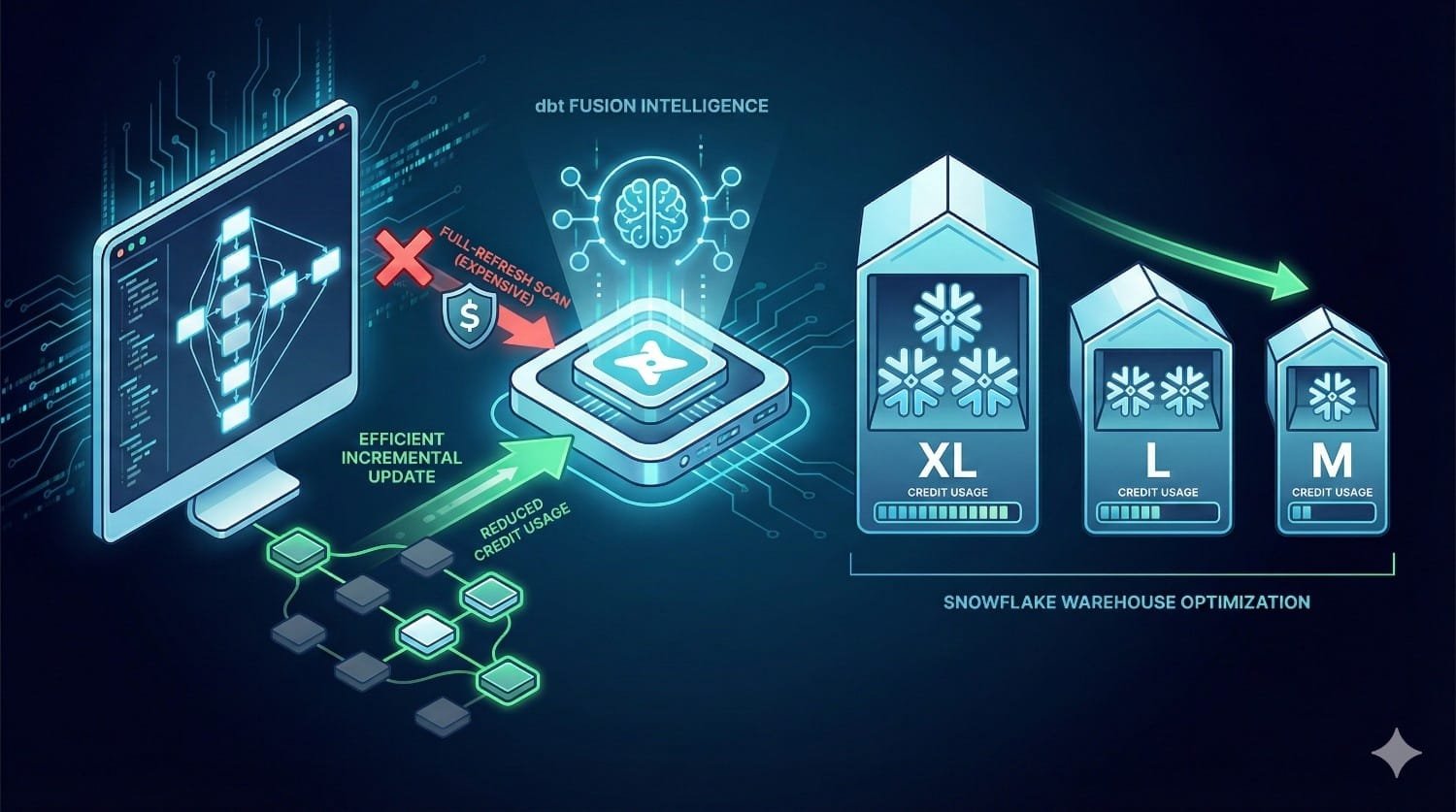
Snowflake pricing is heavily influenced by virtual warehouse size, active compute time, and auto-scaling triggers. dbt Fusion targets these specific billing vectors by drastically reducing active warehouse load. Most organizations report meaningful compute reductions within the first quarter of adoption.
These rapid savings are driven by:
- Avoiding Unnecessary Refreshes: Stopping unchanged models from keeping warehouses awake and burning idle credits.
- Reducing Large-Table Scans: Identifying broken incremental filters before execution to prevent massive spooling.
- Minimizing Overlapping Runs: Intelligently staggering schedules to prevent the engine from unnecessarily spinning up secondary multi-cluster warehouses.
- Pre-Execution Optimization: Optimizing heavy joins and filters in the compiler before they consume active compute resources.
BigQuery Cost Savings: Minimizing Bytes Scanned
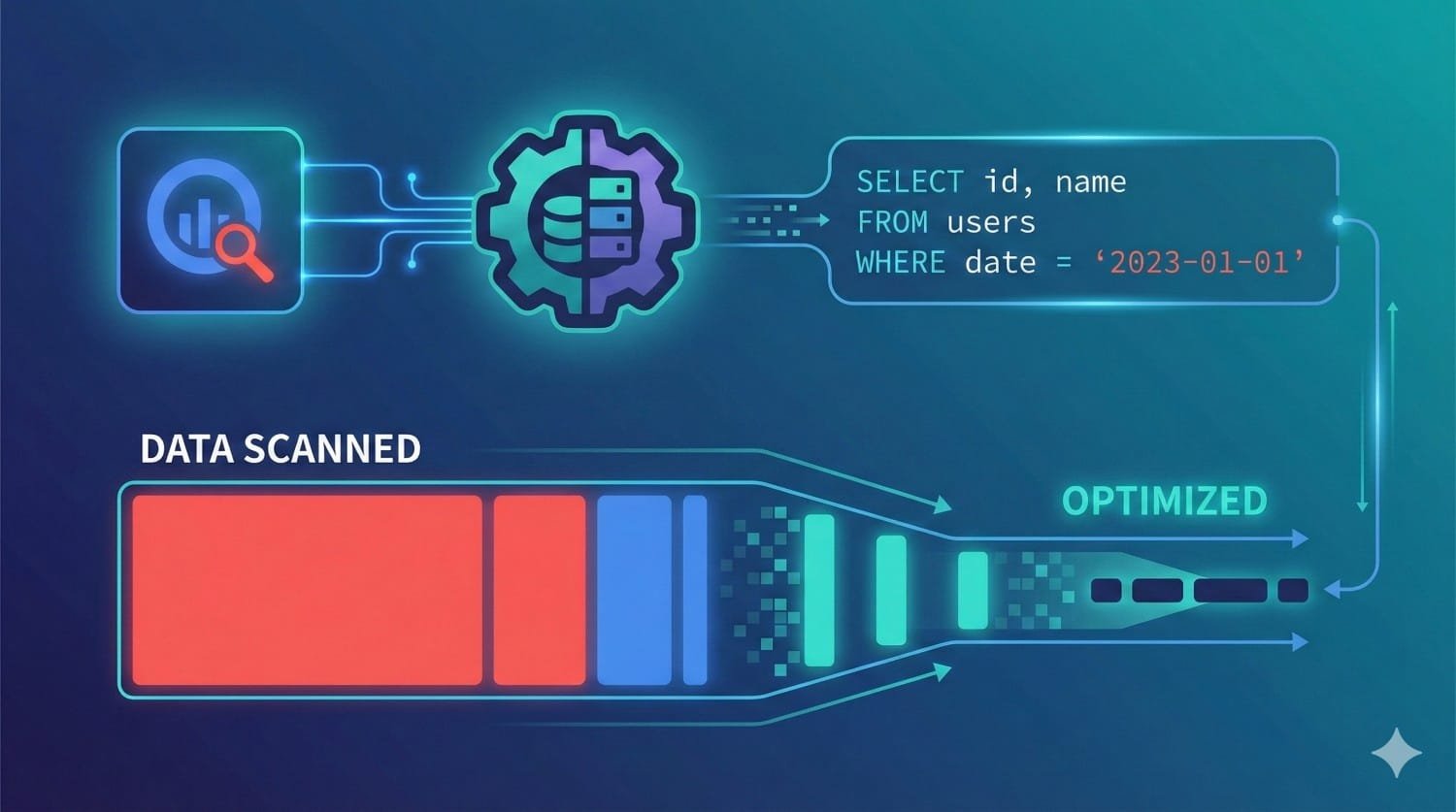
BigQuery utilizes a radically different billing architecture based on the volume of data scanned rather than server uptime. In this environment, SQL efficiency and structural pruning are paramount. dbt Fusion’s Rust engine and metadata framework directly lower on-demand query costs and slot contention by reducing scan volumes.
These savings are driven by:
- Partition-Aware Pruning: Forcing generated SQL to strictly target specific date partitions instead of inadvertently scanning historical logs.
- Aggressive Column Elimination: Stripping out unused columns from intermediate Common Table Expressions (CTEs) before execution.
- Reduced Analytical Redundancy: Eliminating duplicate ad-hoc queries via the unified semantic layer to ensure heavy fact tables are only scanned once.
Who Benefits the Most? The Ideal Organization Profile

While dbt Fusion provides baseline cost-efficiency to any data team, its architecture yields the highest Return on Investment (ROI) for environments suffering from scale-induced friction. If your organization fits any of the profiles below, the transition to metadata-driven orchestration will produce outsized cost reductions.
|
Organizational Profile |
The Core Inefficiency (Legacy dbt) |
The dbt Fusion Advantage |
|
High-Frequency Incremental Pipelines |
Frequent (hourly/daily) updates amplify the cost of poor incremental logic, triggering massive silent full-table refreshes. |
Compile-time validation and dependency-aware execution strictly restrict processing to net-new delta records. |
|
Massive Snowflake & BigQuery Footprints |
Organizations running XL/2XL Snowflake warehouses or paying for massive BigQuery scan volumes face staggering baseline costs. |
Rust-powered SQL pruning, pre-execution cost estimation, and intelligent workload scheduling drop average compute tiers. |
|
Fragmented Multi-BI Environments |
Multiple BI tools (Looker, Tableau, Sigma) independently query the warehouse to compute the exact same metrics repeatedly. |
A centralized semantic layer caches metric definitions globally, eliminating redundant analytical warehouse load. |
|
Siloed Multi-Team Analytics |
Uncoordinated, decentralized development leads to overlapping DAG runs and accidental high-cost operations reaching production. |
Enforced RBAC, model ownership, and strict deployment approval workflows protect production environments. |
|
High-Volume Ad-Hoc Analysis |
Data scientists and analysts running frequent exploratory queries generate inconsistent, unoptimized, and repetitive table scans. |
Semantic pre-aggregations and optimized SQL generation strictly limit the scan volume of exploratory queries. |
|
Low-Governance Environments |
A lack of structural discipline around scheduling, model ownership, and warehouse usage causes runaway monthly cost growth. |
Introduces automated metadata guardrails and immediate cost-estimations in the IDE, enforcing discipline without slowing developer velocity. |
|
High-Volume ETL/ELT Workflows |
Processing massive fact tables and continuous event streams generates tremendous daily processing overhead. |
Eliminates unnecessary table scans and optimizes heavy join logic before it hits warehouse compute resources. |
Is dbt Fusion Worth the Investment?
For many organizations, the financial justification for dbt Fusion is straightforward. When evaluated purely through the lens of Snowflake and BigQuery cost savings, Fusion often becomes a net-positive investment within months.
If your data infrastructure meets any of these three thresholds, Fusion will likely pay for itself within months:
- Snowflake Spend Exceeds $10,000/Month: At this scale, the compute waste generated by unoptimized incremental runs and cascading DAG rebuilds almost always outpaces the licensing cost of Fusion.
- BigQuery Scans Exceed 20 TB/Month: Fusion’s SQL pruning, partition-aware optimization, and semantic-layer consolidation materially reduce scanned bytes, delivering recurring savings that consistently exceed platform fees.
- Your Team Has 5+ Analytics Engineers: Beyond infrastructure costs, Fusion accelerates developer velocity. Features like live previews, compile-time error detection, and strict environment isolation dramatically reduce debugging time and failed production deployments.
The Bottom Line: dbt Fusion is not an additional line-item expense. It operates as a continuous cost-reduction engine, a productivity accelerator, and a governance framework that eliminates the structural inefficiencies of scaling legacy pipelines.
How DataPrism Helps Reduce Snowflake & BigQuery Cost with dbt Fusion
Adopting dbt Fusion is only the first step. The true ROI is unlocked when the platform is paired with optimized architectural patterns, strict governance practices, and deep warehouse optimization. DataPrism partners directly with engineering teams to ensure Fusion functions as a continuous cost-reduction engine rather than just another tool in your stack.
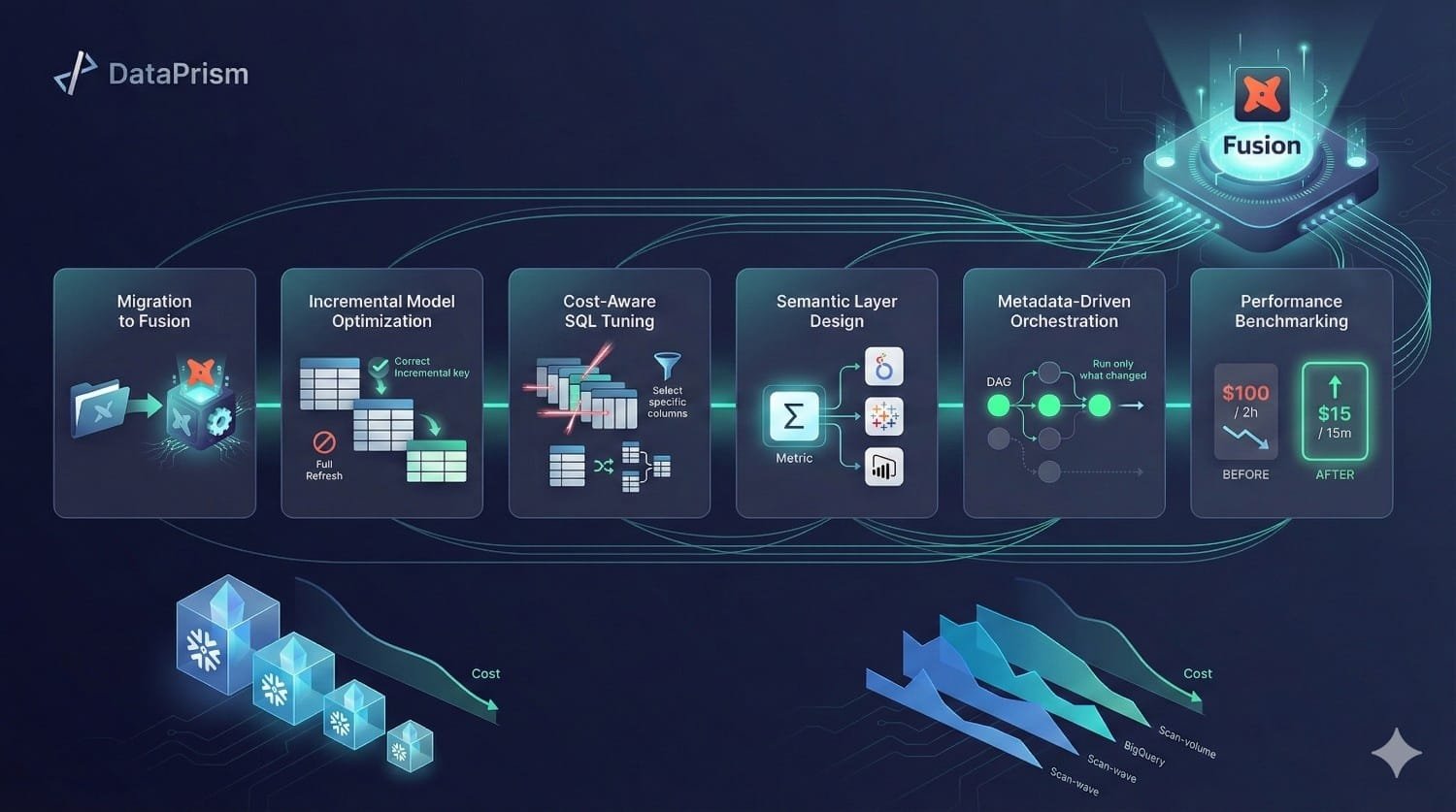
Here is how our specialized Data Engineering Consultants maximize your savings:
1. Seamless Migration & Architecture Auditing
We guide organizations through a highly structured migration from dbt Core to dbt Fusion. This ensures your existing models, lineage dependencies, and tests transition cleanly into Fusion’s metadata-driven framework without disrupting daily operations or analytical SLAs.
2. Restructuring Incremental Logic
Poorly designed incremental architecture is the primary source of warehouse overspending. Our engineers audit your DAGs to validate incremental filters, correct unique key constraints, and enforce true change-only processing to immediately drop Snowflake credits and BigQuery scan volumes.
3. Deep SQL Refactoring
We rewrite legacy transformations into cost-efficient, warehouse-native patterns. By leveraging strict partition pruning, clustered micro-partition principles, and eliminating redundant intermediate scans, we multiply the natural efficiency gains of Fusion’s Rust compiler.
4. Semantic Layer Centralization
We design and deploy a unified semantic architecture that prevents BI tools (like Tableau or Looker) from pounding your warehouse with redundant analytical queries. Centralizing metric definitions permanently eliminates the overhead of repetitive fact-table scans.
5. Intelligent Orchestration & Workload Balancing
We configure Fusion’s metadata-aware orchestrator to execute workloads intelligently. By defining exact run parameters—which models must run, which can be skipped, and when to schedule compute-heavy batch jobs—we prevent peak-hour concurrency scaling and stabilize your cloud invoice.
6. Bottleneck Resolution & Benchmarking
If your teams suffer from slow-running models, stalled pipelines, or heavy joins causing warehouse throttling, DataPrism resolves these bottlenecks using deep diagnostic profiling. We provide clear before-and-after benchmarks tracking runtime improvements, credit reduction, and pipeline reliability.
Conclusion

As data ecosystems expand, treating cloud compute as an infinite resource is no longer a viable business strategy. By shifting from reactive billing analysis to proactive, metadata-driven execution, data teams can significantly reduce their Snowflake and BigQuery overhead. dbt Fusion enables this transition by catching expensive queries during development, eliminating redundant runs, and unifying the semantic layer, ultimately ensuring your data infrastructure scales efficiently.
If your organization is struggling with unpredictable warehouse bills, partnering with an expert consultancy like Data Prism can help you audit your DAGs, optimize your incremental logic, and deploy cost-aware orchestration frameworks tailored to your enterprise.
Book a Free 30-Minute Meeting
Discover how our services can support your goals — no strings attached. Schedule your free 30-minute consultation today and let's explore the possibilities.
Book a Free Call