Introduction
What is Data Migration Testing?
Tailoring Tests to Your Migration Topology
The 3 Essential Phases of Migration Quality Assurance
An enterprise-grade migration testing workflow is divided into three distinct validation gates: Pre-Migration, During Migration (In-Flight), and Post-Migration.
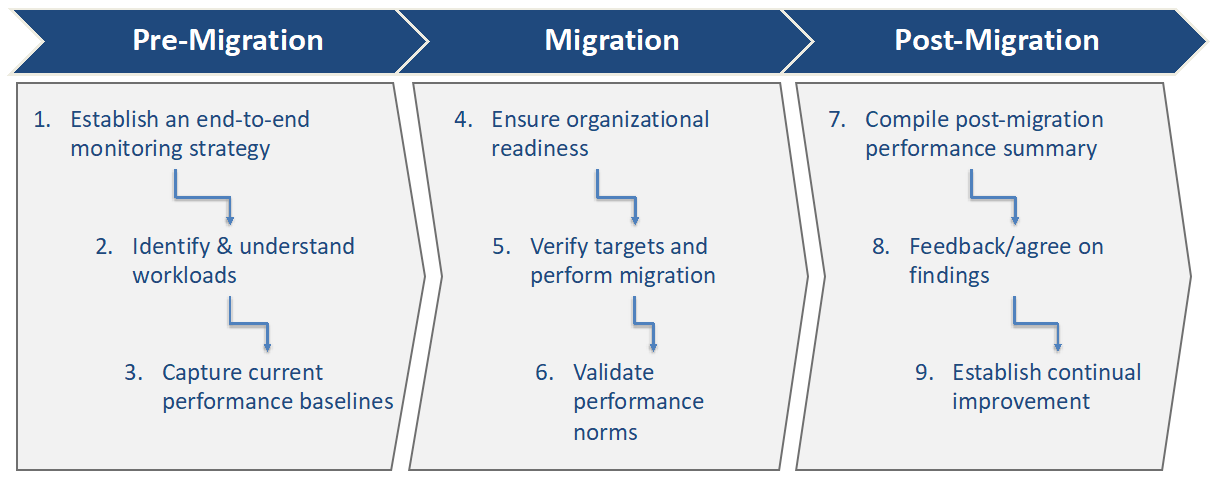
Phase 1: Pre-Migration Testing (The Discovery Gate)
Before moving any infrastructure data, QA teams must establish baseline target variables and audit the state of the source datasets.
- Scope and Volumetric Analysis: Calculate exact source table volumes, row counts, and storage footprints to form a baseline reconciliation log.
- Source Data Profiling and Cleansing: Scan source tables to flag structural technical debt, including null constraints, invalid data strings, and orphan records. For deep verification of raw landing layers, incorporate the automated validation steps outlined in our Data Lake Testing Checklist.
- Schema Definition Mapping: Audit source-to-target field mapping rules to ensure incompatible data types (such as legacy VARCHAR variants converting to structured JSON blocks) scale accurately.
- Immutable Snapshot Isolation: Take complete point-in-time cold backups of all historical storage systems to provide a safe restore point if a catastrophic failure occurs during cutover.
Phase 2: In-Flight Migration Testing (The Execution Gate)
This phase monitors active data transformations and transit pipelines as records stream between infrastructure points.
- Subset and Sample Ingestion Testing: Execute initial migrations using small, representative testing subsets (e.g., 5% to 10% of records) to verify schema mapping accuracy before running full bulk processing pipelines.
- Transit Security Auditing: Verify network security parameters to ensure that data in transit is protected using robust encryption protocols, such as TLS 1.3.
Phase 3: Post-Migration Testing (The Reconciliation Gate)
The post-loading gate confirms system usability and provides complete data completeness checks across the new architecture.
- Full Quantified Reconciliation: Compare destination record totals against baseline source metrics to ensure zero data loss during transit.
- Target Functional Validation: Run regression testing sweeps across downstream applications to ensure the target software can read, update, and process the migrated records flawlessly.
- Data Formatting and Mismatch Identification: Verify character encodings, decimal placements, and time zone configurations across target environments to prevent corruption.
- User Acceptance Testing (UAT): Bring operational business units into the system to run daily tasks, ensuring that the final target layer matches real-world business needs.
To structure your QA process, your engineering team should utilize standardized test cases. Here is a production-ready framework for your testing logs:
|
Test Case ID |
Validation Target |
Execution Step |
Expected Result |
|
TC-001 |
Completeness |
Run COUNT(*) cross-system queries. |
Target row totals exactly match source row totals (Zero data drop). |
|
TC-002 |
Accuracy |
Execute MD5/SHA-256 block-level checksums. |
Cryptographic hashes match, proving perfect bit-level transit. |
|
TC-003 |
Integrity |
Query target primary/foreign key relationships. |
No orphaned records exist; relational tables are perfectly linked. |
|
TC-004 |
Transformation |
Verify legacy string dates converted to standard timestamps. |
All localized strings resolve to standardized cloud timestamp formats. |
Critical Technical Challenges to Mitigate
Enterprise Best Practices for Pipeline Validation
Conclusion: Securing Pipeline Integrity
Book a Free 30-Minute Meeting
Discover how our services can support your goals — no strings attached. Schedule your free 30-minute consultation today and let's explore the possibilities.
Book a Free Call