
Introduction
What Is Data Integration?
Types of Data Integration Frameworks
Understanding the Basics: ETL vs. ELT
A primary point of comparison when reviewing data integration solutions is identifying when data transformation occurs. This divides your architectural options into two primary categories:
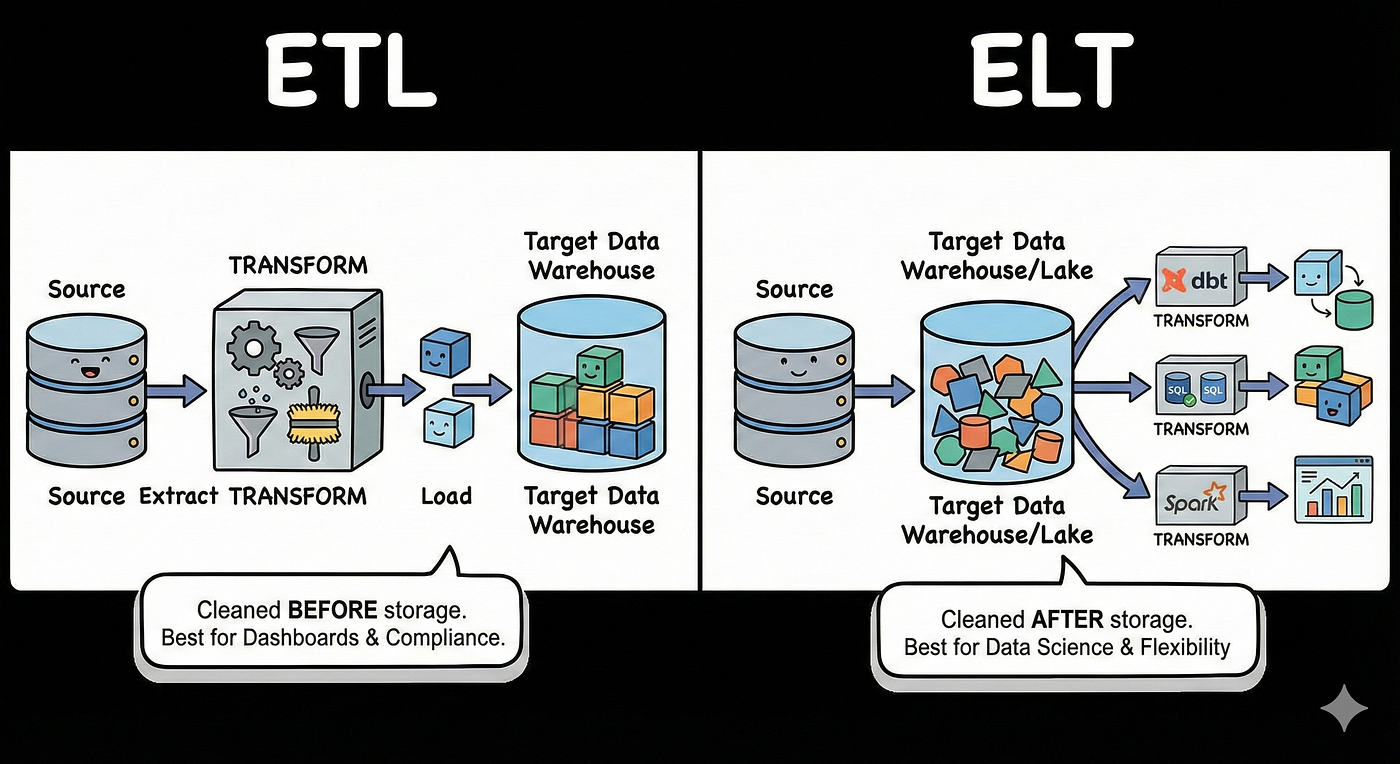
- ETL (Extract, Transform, Load): Because data is transformed before hitting its final destination, this framework guarantees that only highly sanitized, structured, and compliant records enter your data ecosystem. It is the safest route for legacy infrastructure or strict data governance frameworks.
- ELT (Extract, Load, Transform): This cloud-native framework prioritizes speed by shifting the transformation step into the target data warehouse. Because modern cloud storage and compute scale independently and cost-effectively, ELT allows data teams to store raw data immediately and apply modeling layers downstream as business logic evolves using modern frameworks like dbt (data build tool).
Core Criteria: How to Judge Integration Solutions
The Evaluation Process: A Step-by-Step Guide

Follow a structured engineering proof-of-concept (POC) rather than buying solutions based purely on vendor documentation:
- Step 1: Map Your Existing Topology: Document all active data sources (production databases, external APIs, scraped property or real estate endpoints) and target destinations (warehouses, lakes).
- Step 2: Execute a Staged Race: Deploy two or three competing tools in a test environment. Connect them to identical source sandboxes, execute a synchronized run, and measure deployment complexity, resource consumption, and ingestion speeds.
- Step 3: Analyze the Total Cost of Ownership (TCO): Review pricing models carefully. Legacy enterprise tools often require flat annual software licenses, while cloud-native integration platforms bill continuously based on rows synced or compute credits consumed. Project these costs out across your anticipated data scaling trajectory.
- Step 4: Assess Schema Drift Management: Evaluate how each software option handles unexpected structural changes. If a source database changes a column type or an API alters its JSON payload, the integration platform should intelligently alert data teams or handle the drift without breaking the downstream pipeline.
Tailoring Tests to Your Migration Topology
The Data Migration Test Case Matrix
Evaluation of Leading Data Integration Platforms
Best Practices You Should Implement
Conclusion
Book a Free 30-Minute Meeting
Discover how our services can support your goals — no strings attached. Schedule your free 30-minute consultation today and let's explore the possibilities.
Book a Free Call